-
Incident report
-
Resolution: Cannot Reproduce
-
 Critical
Critical
-
None
-
1.8.10
-
Linux (EL 6), Mysql (5.1)
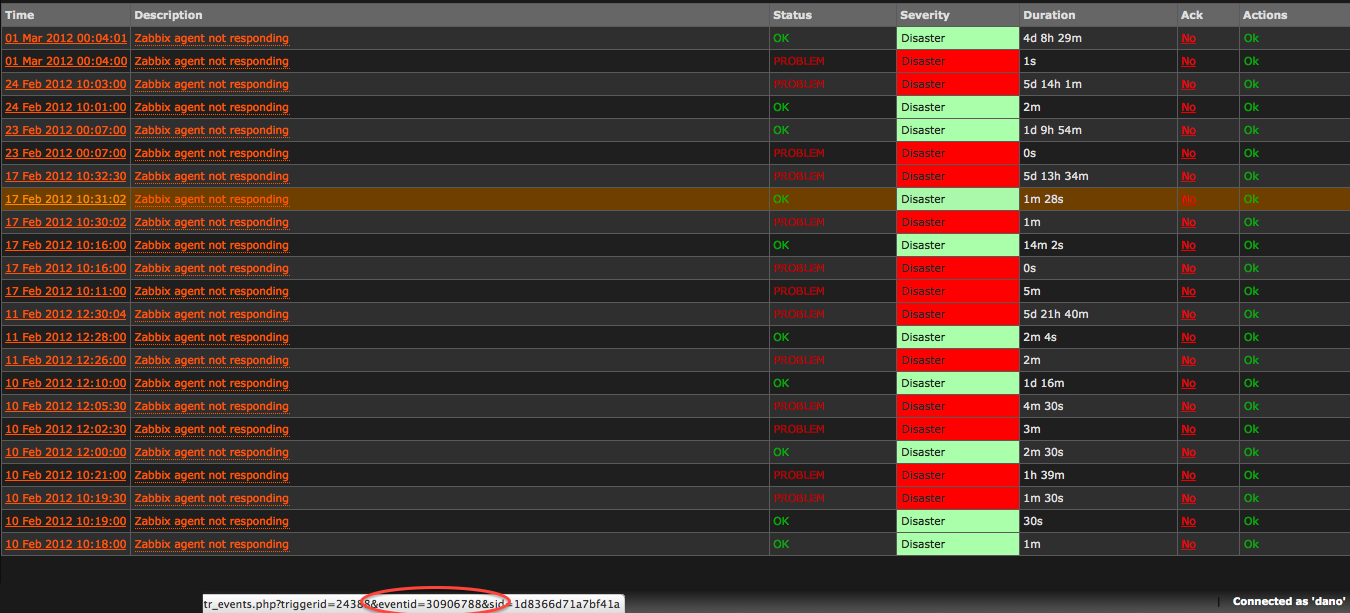
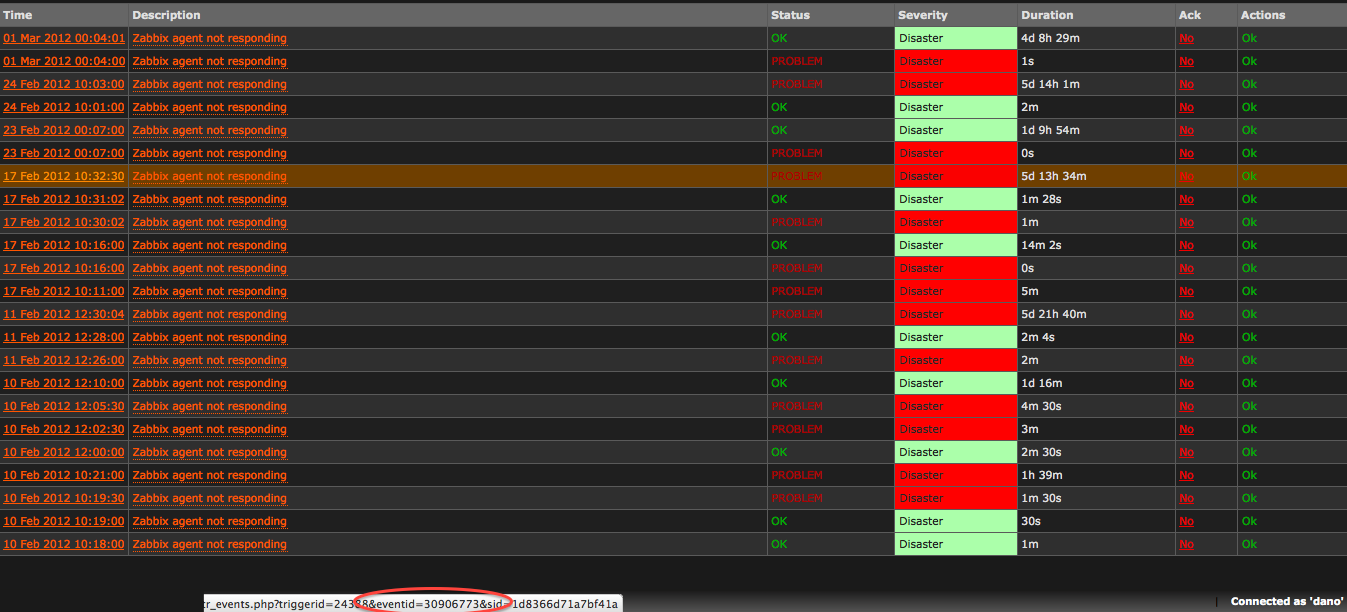
Sometimes we observe a situation when zabbix produces false positive alerts (based on trigger
{agent.ping.nodata(180)}=1) during high IO load on the server (i.e. while running a backup on FS, which holds the zabbix database). We suppose that this leads to a problem when events are stored in switched order, which is probably caused by wrong clock values. Although the event IDs seem to be stored in right order (please see the attached pictures). The Availability report generates then graphs with hosts mostly down.
Maybe this is somehow related to #ZBX-4466.