|
Causes |
|||
| causes |
|
VMware Datastore usage mismatch | Closed |

[ZBX-15417] VMWare datastore monitoring loses *all* history and trends when Zabbix can't get the data once Created: 2019 Jan 07 Updated: 2024 Apr 10 Resolved: 2019 Jan 28 |
|
| Status: | Closed |
| Project: | ZABBIX BUGS AND ISSUES |
| Component/s: | Proxy (P), Server (S) |
| Affects Version/s: | 4.0.3 |
| Fix Version/s: | 4.0.4rc1, 4.2.0alpha3, 4.2 (plan) |
| Type: | Problem report | Priority: | Major |
| Reporter: | Marco Jakobs | Assignee: | Michael Veksler |
| Resolution: | Fixed | Votes: | 2 |
| Labels: | None | ||
| Remaining Estimate: | Not Specified | ||
| Time Spent: | Not Specified | ||
| Original Estimate: | Not Specified | ||
| Attachments: |
|
||||||||
| Issue Links: |
|
||||||||
| Team: | |
||||||||
| Sprint: | Sprint 48, Jan 2019 | ||||||||
| Story Points: | 0.5 | ||||||||
| Description |
|
Steps to reproduce: I'm periodically loose all history and trends data of random VMWare datastore from my hosts. There are 1-2 "loss events" per day. Data losses are random in time and affected host. It only affects datastore performance data, all other VMWare data are not showing the issue.
Result: All historical data before the "loss event" is erased in Zabbix (see screenshot). Whenever such an event happens on any datastore / any host, I see this line in the zabbix_server.log: 9664:20190107:132024.877 Cannot get Datastore info: Timeout was reached.
Expected: I have enough VMWare collectors enabled and I have increased them from 10 to 30 with a timeout of 30s (was 10 before) each, this did not help. Also no other VMWare performance data but datastore data is affected. I would expect that - even if the datastore performance could not be fetched once in any minute - that only this certain minute-value would be missing/not available, but under no circumstances this should lead to a complete loss of all previous historical data! |
| Comments |
| Comment by Edgars Melveris [ 2019 Jan 08 ] |
|
Hello Marco! |
| Comment by Marco Jakobs [ 2019 Jan 08 ] |
|
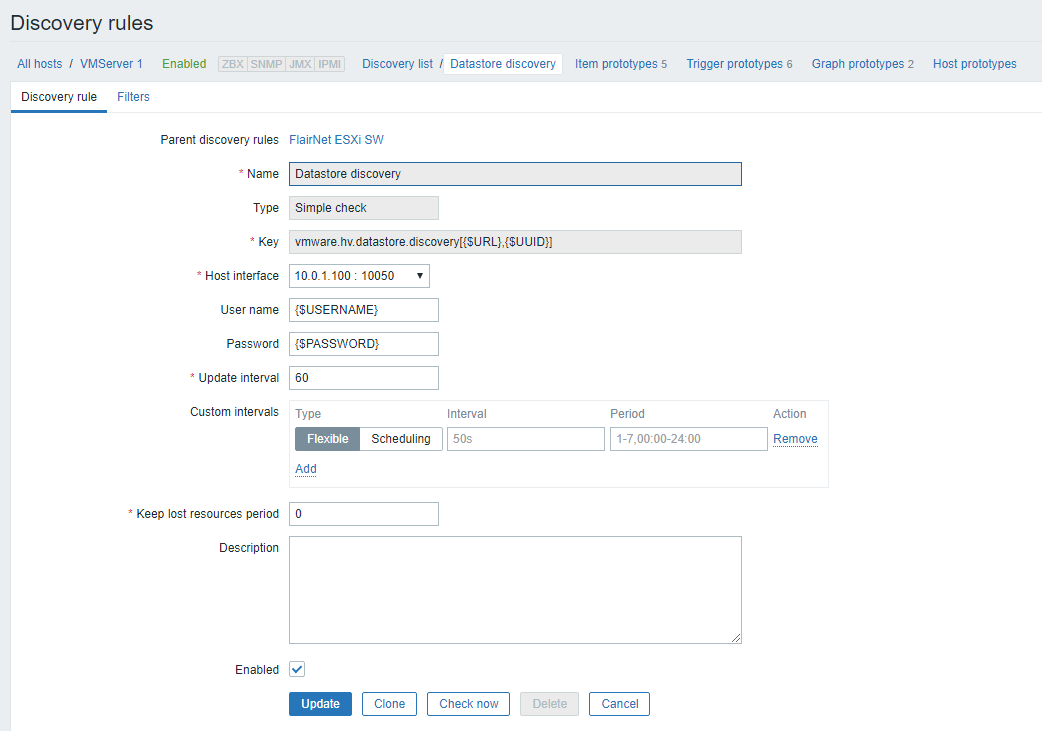
Hi Edgars, yes, that's based on the standard template. Please see attached the screenshot of the discovery rule.
|
| Comment by Marco Jakobs [ 2019 Jan 08 ] |
|
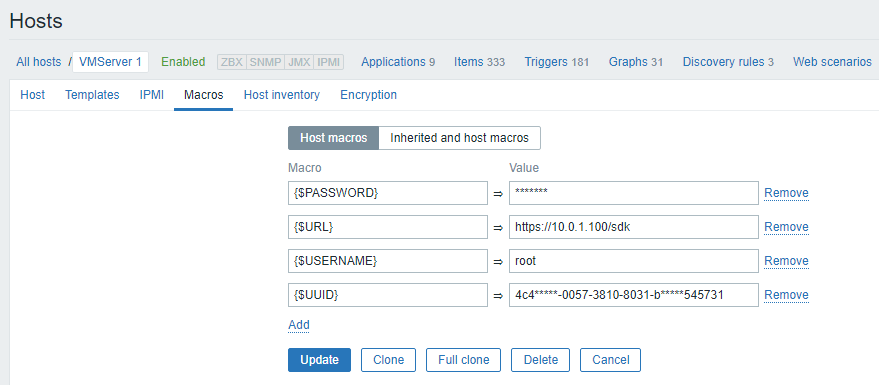
Here are the Macros (a bit "anonymized")
|
| Comment by Glebs Ivanovskis [ 2019 Jan 08 ] |
|
There is a bug. Information about each datastore is being requested separately and in case something went wrong (e.g. a "Timeout was reached.") the datastore will be simply omitted and I guess won't be present in LLD JSON. As a result Zabbix will treat this datasource as "lost" and will remove according to Keep lost resources setting. |
| Comment by Edgars Melveris [ 2019 Jan 08 ] |
|
I will speak to the developers about what cyclone said, but aside from that - you should increase the "Keep lost resources" setting to something reasonable (the default is 30 days), otherwise the item gets deleted every time the discovery rule doesn't find it. That's why your history is gone. And then gets recreated the next time discovery rule finds this datastore, but of course with empty history. |
| Comment by Marco Jakobs [ 2019 Jan 08 ] |
|
Good point! Strange, I did not change it to 0 ... and in the "sister template" it's 30d. I've reset it to 30d. As far as I understand Glebs I'll loose 60 mins of history is something went wrong then? (My discovery interval is 60 minutes) |
| Comment by Edgars Melveris [ 2019 Jan 08 ] |
|
Not necessarily, it will go into unsupported state, but depending on how often you check unsupported items, will start collecting data after it's up again. The main issue is probably why it times out regularly |
| Comment by Glebs Ivanovskis [ 2019 Jan 08 ] |
|
No. "Lost" (not discovered) items are still first class citizens and will still be checked, so you should not loose any data. You will just get an annoying icon next to the item in Configuration saying that it will be deleted in 30 days. |
| Comment by Michael Veksler [ 2019 Jan 16 ] |
|
The situation is possible in case of monitoring esxi without vcenter only. Unfortunately, in situation without vcenter, esxi does not provide perfCounter metrics for get info about DS state. This is the reason why we have to get information about DS state from the configuration of DS. But not everything so simple... The reasonable solution is to increase the value of VMwareTimeout. |
| Comment by Marco Jakobs [ 2019 Jan 17 ] |
|
I'm running ESXi with vCenter, but intentionally I'm monitoring the hosts directly with Zabbix. Otherwise vCenter would be the single point of failure for all the ESXi monitoring. Since correcting the "Keep lost resources" back to 30d I did at least not see a loss of datastore performance data anymore. But a question concerning this: vmware version <6.0 does not update configuration (free space and etc...) of DS. That is why we call "refresh" function for DS. But "refresh" configuration for DS is an extremely heavy operation I'm using ESXi 6.5, but from your post I did not see if Zabbix is "intelligent" enough to not call the refresh function of ESXi version 6 and above where it's not needed. I think it's still calling the refresh as I'm seeing timeouts. Shouldn't be the proper way to not call the refresh where it's not needed (ESXi 6.0 and above) to save resources? |
| Comment by Glebs Ivanovskis [ 2019 Jan 17 ] |
|
It's alarming that issue now Needs documenting without any fix provided.
Sure, it can, but it must not have such catastrophic consequences.
Even then timeout can still occur. Don't advertise a workaround as a solution. wiper: I think the consequences are pretty reasonable. Zabbix cannot know why the request timeouted, was it one time network issue, is the network down for longer time period or simply VMware timeouts the specific request. So Zabbix returns resources it could gather, making the timeouted resources 'lost'. The alternative would be to fail the data gathering process, making all VMware items notsupported. cyclone: I guess reporter will disagree that consequences are reasonable.
I think Zabbix should assume it was a temporary network issue or VMware simply needs more time to process the request (in which case Zabbix should urge user to increase VMwareTimeout). At this step Zabbix has been already authorized by VMware service (right?) therefore VMware is reachable and it can't be a timeout due to misconfigured URL or something. VMware can't simply decide to "time out the specific request" because:
Usually Zabbix nicely separates discovery and data collection. According to the logic I would expect LLD rule to become "not supported". Some of discovered items may get a new value, some (timeouted) may become "not supported". (But it would be OK for all of them to become "not supported" for simplicity) None should become "lost". <dimir> Going "not supported" sounds perfect. |
| Comment by Glebs Ivanovskis [ 2019 Jan 21 ] |
|
It seems that ChangeLog message does not match the code and comments in this ticket:
Code: #define ZBX_VMWARE_DS_REFRESH_VERSION 6 ... ... ZBX_VMWARE_DS_REFRESH_VERSION > atoi(service->version) ... Changelog: perform datastore configuration refresh only when directly monitoring ESXi version v6.0 or lower Shouldn't "v6.0 or lower" become "lower than v6.0" / "below v6.0"? wiper: Thanks, fixed. |
| Comment by Marco Jakobs [ 2019 Jan 22 ] |
|
Just a note, I guess it might be related to this: Two days ago the data store latency values of one of my hosts suddenly disappeared and no new values have been recorded anymore. Data store free worked. Latency values were shown as not supported. Although running through several discovery periods this did not fix within 24 hours. I needed to restart the zabbix-server process to have data store latency values on this host being recorded again. Previous history was preserved and not deleted, I just have a "gap" over two days. |
| Comment by Glebs Ivanovskis [ 2019 Jan 22 ] |
|
Have you tried increasing VMwareTimeout as suggested? |
| Comment by Marco Jakobs [ 2019 Jan 22 ] |
|
Yes, I did ... maybe not enough. I've increased it to 40 now ... |