[ZBX-15899] Inconsistent behavior of regex for UTF-8 input Created: 2019 Mar 29 Updated: 2024 Apr 10 Resolved: 2019 Jun 08 |
|
| Status: | Closed |
| Project: | ZABBIX BUGS AND ISSUES |
| Component/s: | Agent (G), Frontend (F), Proxy (P), Server (S) |
| Affects Version/s: | 4.2.0rc2 |
| Fix Version/s: | 4.0.10rc1, 4.2.4rc1, 4.4.0alpha1, 4.4 (plan) |
| Type: | Problem report | Priority: | Minor |
| Reporter: | Vjaceslavs Bogdanovs | Assignee: | Andris Mednis |
| Resolution: | Fixed | Votes: | 0 |
| Labels: | None | ||
| Remaining Estimate: | Not Specified | ||
| Time Spent: | Not Specified | ||
| Original Estimate: | Not Specified | ||
| Attachments: |
|
| Team: | |
| Sprint: | Sprint 50 (Mar 2019), Sprint 51 (Apr 2019), Sprint 52 (May 2019), Sprint 53 (Jun 2019) |
| Story Points: | 2 |
| Description |
|
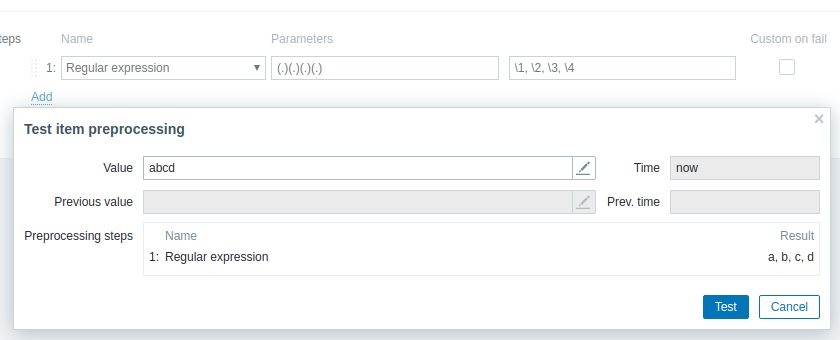
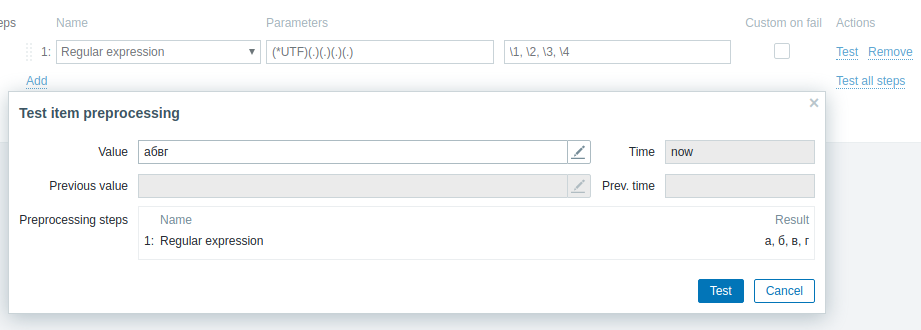
Currently Regex matching is not consistent between input strings and Zabbix components.
Currently, in order for regex to work correctly on Server (as well as on Agent and Proxy), utf flag should be set like so "(*UTF)(.)(.)(.)(.)" (without quotes): It is expected for Server to work with UTF-8 by default. |
| Comments |
| Comment by Andris Mednis [ 2019 Apr 30 ] |
|
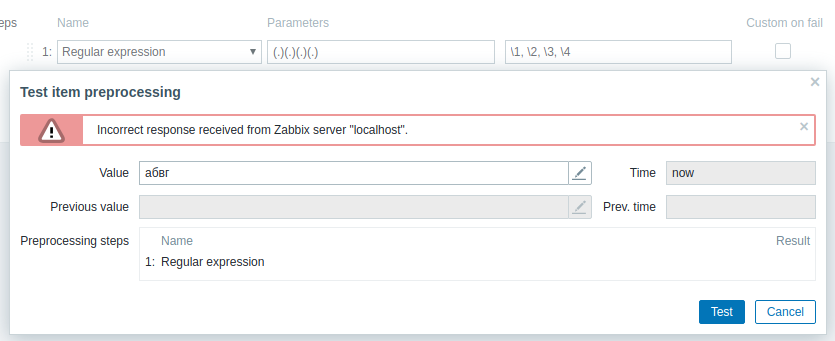
Another observation - If preprocessing described above is used for log item with "абвг" then it results in error when inserting into DB: 21479:20190430:161232.568 query [txnlev:1] [insert into history_log (itemid,clock,ns,timestamp,source,severity,value,logeventid) values (28566,1556629952,74650973,0,'',0,'<D0>, ',0); ] 21479:20190430:161232.569 [Z3005] query failed: [0] PGRES_FATAL_ERROR:ERROR: invalid byte sequence for encoding "UTF8": 0xd0 0x2c [insert into history_log (itemid,clock,ns,timestamp,source,severity,value,logeventid) values (28566,1556629952,74650973,0,'',0,'<D0>, ',0); ] 21479:20190430:161232.569 query [insert into history_log (itemid,clock,ns,timestamp,source,severity,value,logeventid) values (28566,1556629952,74650973,0,'',0,'<D0>, ',0); ] failed, setting transaction as failed 21479:20190430:161232.569 commit called on failed transaction, doing a rollback instead |
| Comment by Vladislavs Sokurenko [ 2019 May 14 ] |
|
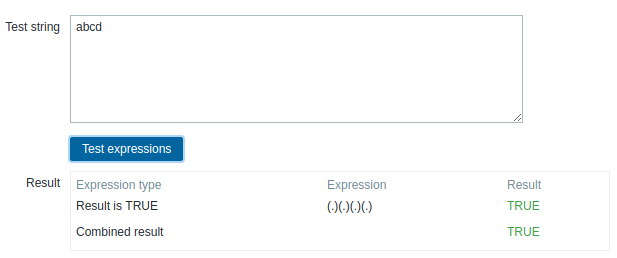
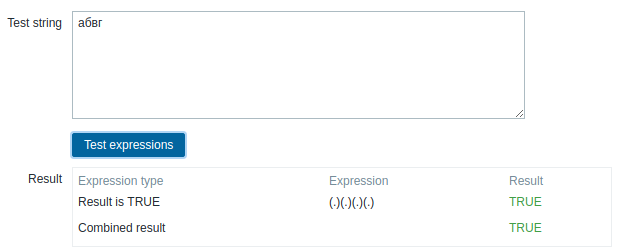
Description of the task seem a bit misleading as it mentions that Zabbix server work differently from frontend, while it actually don't. (.)(.)(.)(.) Test string: абвг It says result is TRUE Yes that is correct but so is such expression: (.)(.)(.)(.)(.)(.)(.)(.) Test string: абвг So basically it is matching 4 bytes but if you supply 8 it will match them too. Please confirm ? vjaceslavs Double checked everything. Looks like PHP treats regex the same way as server (breaks string in the midle of UTF sequences). vso this solve the issue for the frontend part: diff --git a/frontends/php/include/classes/regexp/CGlobalRegexp.php b/frontends/php/include/classes/regexp/CGlobalRegexp.php index 1cb115b2d4..417605e1d4 100644 --- a/frontends/php/include/classes/regexp/CGlobalRegexp.php +++ b/frontends/php/include/classes/regexp/CGlobalRegexp.php @@ -165,7 +165,7 @@ class CGlobalRegexp { private static function buildRegularExpression(array $expression) { $expression['expression'] = str_replace('/', '\/', $expression['expression']); - $pattern = '/'.$expression['expression'].'/m'; + $pattern = '/'.$expression['expression'].'/mu'; if (!$expression['case_sensitive']) { $pattern .= 'i'; } As andris mentioned this:
u (PCRE_UTF8)
This modifier turns on additional functionality of PCRE that is incompatible with Perl. Pattern and subject strings are treated as UTF-8. An invalid subject will cause the preg_* function to match nothing; an invalid pattern will trigger an error of level E_WARNING. Five and six octet UTF-8 sequences are regarded as invalid since PHP 5.3.4 (resp. PCRE 7.3 2007-08-28); formerly those have been regarded as valid UTF-8.
|
| Comment by Vladislavs Sokurenko [ 2019 May 14 ] |
|
(3) [D] There are performance considerations if we are forcing UTF-8 see
vjaceslavs We should force UTF-8 because Zabbix is an UTF application. It is like taking into consideration that supporting both upper case and lower case letters is slower that supporting only one set. This could be true, but our solution should work for everyone. vso updated to documentation sub issue, this should be mentioned in upgrade notes in case anyone runs into issues. andris It was decided to not enforce UTF-8. CLOSED |
| Comment by Andris Mednis [ 2019 Jun 05 ] |
|
Available in:
|