|
Problem description: Problem time and SLA is calculated differently for Services based on the same trigger at specific display periods if the service uptime period differs for these services. For example:
Service #1 (based on trigger 1) has uptime period set to "Monday 14:00 - Monday 16:00" and service #2 (based on trigger #1) has uptime period set to "Monday 14:00 - Monday 15:00".
Currently the service is in status problem. For period in ['Today', 'This week', 'This month', 'This year', 'Last 24 hours'] the SLA and problem time values of the two services are almost equal, but if period is set to "Last 7 days", "Last 30 days" or "Last 365 days" - problem time of service #1 has problem time 2 times less than service #2.
Steps to reproduce:
1. Create a host, a zabbix trapper item and a trigger for this item, with severity higher that "Information".
2. Navigate to Configuration => Services and create 2 services with SLA calculation based on the previously created trigger:
- For service #1 set the uptime period for 1 hour (current time must be part of this period).
- For service #2 set the uptime period for 2 hours (current time must be part of this period).
3. Set the trigger in status problem.
4. Navigate to Monitoring => Services and make sure that the "Problem time" has started to increase for both services.
5. Change the period to be displayed - set all of the values one by one.
Result: For some of the periods the problem time and the SLA values are almost equal for the two services (today, this week, this month and last 24 hours), but for some periods for service #1 they are two times larger than for service #2 (this year, last 7 days, last 30 days, last 365 days).
Expected: Such difference of behavior should not be observed - we either take into account the length of the uptime period, or we don't.
Example: 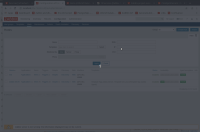
|