|
Duplicate |

[ZBX-17108] unreal spike logged for internal processes (more than 100% busy) on graphs, caused by major upgrade Created: 2019 Dec 20 Updated: 2024 Apr 10 Resolved: 2020 Mar 04 |
|
| Status: | Closed |
| Project: | ZABBIX BUGS AND ISSUES |
| Component/s: | Proxy (P), Server (S) |
| Affects Version/s: | 4.0.15, 4.4.3, 5.0 (plan) |
| Fix Version/s: | 4.0.19rc1, 4.4.7rc1, 5.0.0alpha3, 5.0 (plan) |
| Type: | Problem report | Priority: | Minor |
| Reporter: | Oleksii Zagorskyi | Assignee: | Martins Abele |
| Resolution: | Fixed | Votes: | 0 |
| Labels: | internalmonitoring, spike, upgrade | ||
| Remaining Estimate: | Not Specified | ||
| Time Spent: | Not Specified | ||
| Original Estimate: | Not Specified | ||
| Attachments: |
|
||||
| Issue Links: |
|
||||
| Team: | |
||||
| Sprint: | Sprint 59 (Dec 2019), Sprint 60 (Jan 2020), Sprint 61 (Feb 2020), Sprint 62 (Mar 2020) | ||||
| Story Points: | 0.25 | ||||
| Description |
|
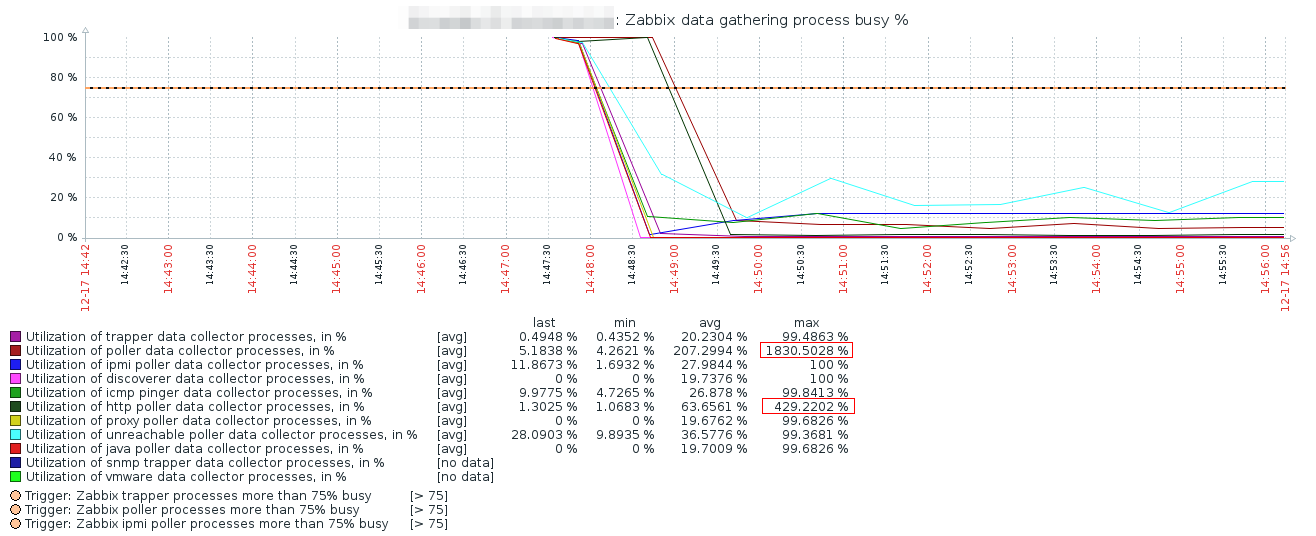
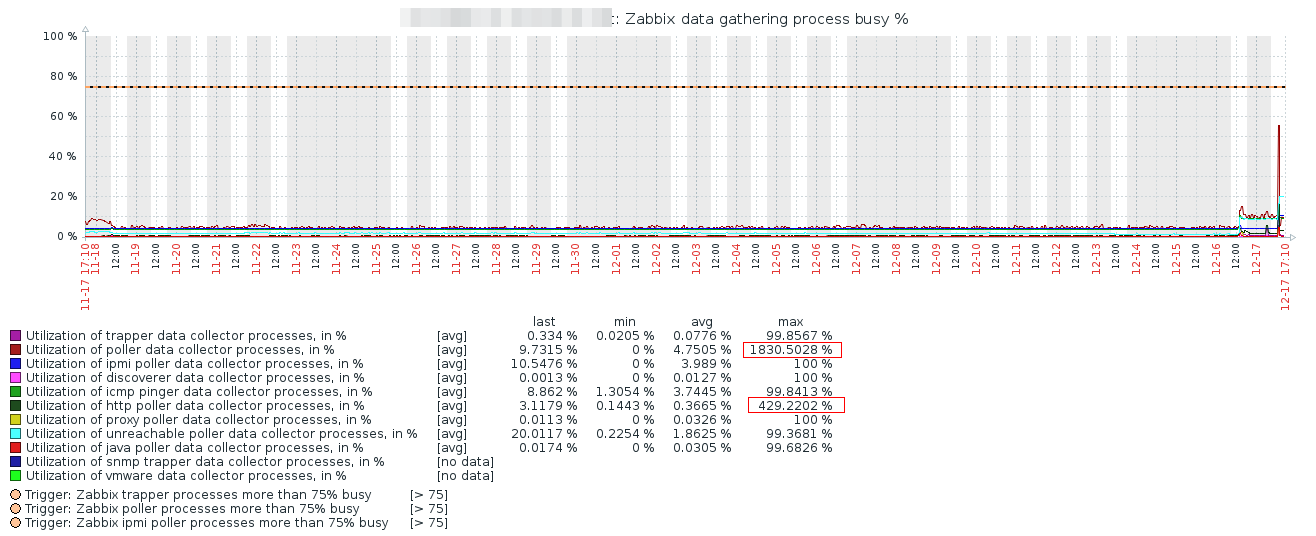
Here is major 3.4 -> 4.4 upgrade log: 5159:20191217:143705.304 Starting Zabbix Server. Zabbix 4.4.3 (revision 6cad6f888e). 5159:20191217:143705.304 ****** Enabled features ****** 5159:20191217:143705.304 SNMP monitoring: YES 5159:20191217:143705.304 IPMI monitoring: YES 5159:20191217:143705.304 Web monitoring: YES 5159:20191217:143705.304 VMware monitoring: YES 5159:20191217:143705.305 SMTP authentication: YES 5159:20191217:143705.305 ODBC: YES 5159:20191217:143705.305 SSH2 support: YES 5159:20191217:143705.305 IPv6 support: YES 5159:20191217:143705.305 TLS support: YES 5159:20191217:143705.305 ****************************** 5159:20191217:143705.305 using configuration file: /etc/zabbix/zabbix_server.conf 5159:20191217:143705.317 current database version (mandatory/optional): 03050046/03050046 5159:20191217:143705.317 required mandatory version: 04040000 5159:20191217:143705.317 starting automatic database upgrade ... 5159:20191217:144529.032 completed 100% of database upgrade 5159:20191217:144529.033 database upgrade fully completed 5159:20191217:144538.309 starting event name update forced by database upgrade 5159:20191217:144539.126 completed 1% of event name update ... 5159:20191217:144732.434 completed 99% of event name update 5159:20191217:144732.823 completed 100% of event name update 5159:20191217:144732.829 event name update completed 5159:20191217:144733.292 server #0 started [main process] 5528:20191217:144733.294 server #1 started [configuration syncer #1] 5529:20191217:144733.294 server #2 started [ipmi manager #1] .... 5689:20191217:144734.088 server #158 started [preprocessing worker #1] 5661:20191217:144734.299 cannot process proxy "zabbixproxy-01.xxxxx": protocol version 3.4 is not supported anymore .... normal operations (ignore initial dbversion 03050046, caused by first failed attempt) See legend on graphs, history: Such numbers may mislead, so zabbix should not calculate such wrong numbers. Maybe it's caused by specific change in 4.0 - exiting events name update. But, after the upgrade, I needed to restart zabbix server a few times. And every time after restart, server logs 100% busy spikes for many "internal process busy level" items. |
| Comments |
| Comment by richlv [ 2019 Dec 20 ] |
|
A common practice is to add maintenance period before a restart. |
| Comment by Oleksii Zagorskyi [ 2019 Dec 20 ] |
|
It's very inefficient to do play with "temporal" maintenance. And problem is not with alerts (IMO), but with graphs, which because of values like 100% starts to use bad scaling. So restart makes graphs understanding bad. |
| Comment by Martins Abele [ 2020 Mar 03 ] |
|
Fixed in:
|