|
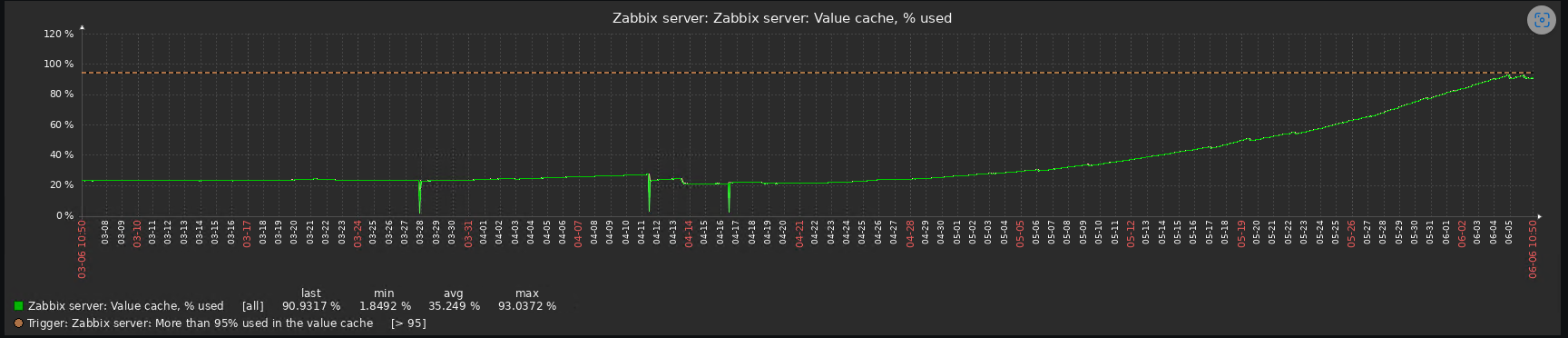
I don't know if it's related but I upgraded to 6.4.13 in April and my value cache size is increasing since then. I'll upgrade to the latest and hope it fixes the issue.
|
|
Same thing.
Periodically dealing with value cache exponential leaks on different Zabbix installations after one of the latest 6.4.x upgrades (can't mention the exact one).
|
|
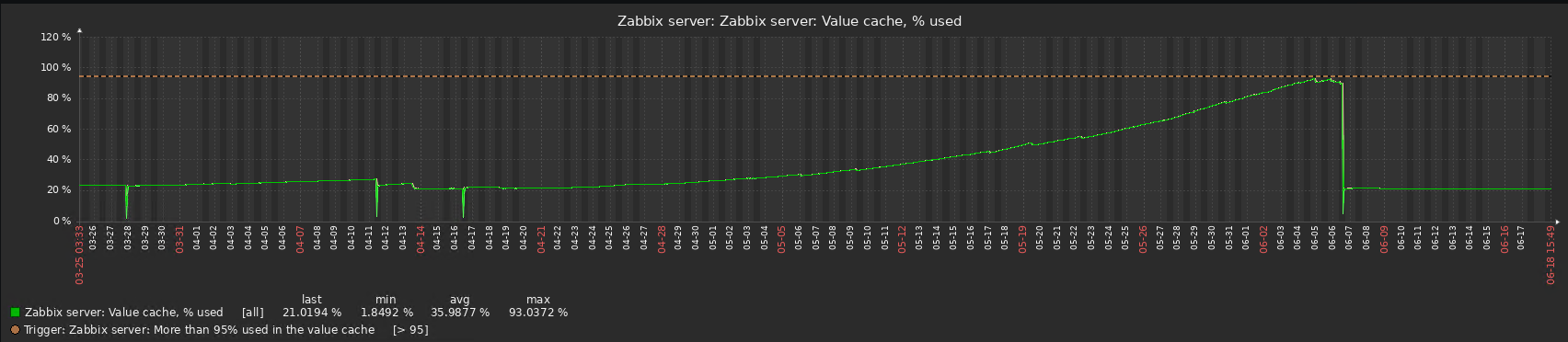
The bug must have been fixed. I don't see the same problem in 6.4.15.
|
|
Thank you for your comments. It seems the same but may be it is not. In short my problem is: when zabbix server is restarting, exactly restart procedure is fast. The problem begins after that. There is growing delay appears in items execution. For example I have the availability items (agent.ping) with interval 1 minute. I see theese items has last exec time 2, 3, 4,... 20 minutes ago. Also theese items are coming "nodata" during this process and it occurs switching all the triggers, which has nodata in expression. It generates hundreds and thousands of alerts. Watching for server start and getting diaginfo=valuecache I''ve seen that server downloads very large datasets for for all items. All theese items used in trigger expressions with very short intervals: not longer than 20 minutes, but I've seen a thousands of downloaded values for it in valuecache. It means server downloads values for about a week, or longer. Why does it do it, if it needs just several? I think that is a reason of my problem with items execution delay.
I've tried to patch sources like that:
--- a/src/libs/zbxhistory/history_elastic.c
+++ b/src/libs/zbxhistory/history_elastic.c
@@ -645,17 +645,27 @@ static int elastic_get_values(zbx_history_iface_t *hist, zbx_uint64_t itemid, in
{
zbx_elastic_data_t *data = hist->data.elastic_data;
size_t url_alloc = 0, url_offset = 0, id_alloc = 0, scroll_alloc = 0, scroll_offset = 0;
- int total, empty, ret;
+ int total, empty, ret, new_start, range_limit;
CURLcode err;
struct zbx_json query;
struct curl_slist *curl_headers = NULL;
char *scroll_id = NULL, *scroll_query = NULL, errbuf[CURL_ERROR_SIZE];
CURLoption opt;
+ range_limit = 1200;
zabbix_log(LOG_LEVEL_DEBUG, "In %s()", __func__);
ret = FAIL;
+ if (end - start > range_limit) {
+ new_start=end-range_limit;
+ zabbix_log(LOG_LEVEL_DEBUG, "[HISTSYNC] Correct time range for itemid %d: start %d --> %d.", itemid, (int)start, (int)new_start);
+ start=new_start;
+ zabbix_log(LOG_LEVEL_DEBUG, "[HISTSYNC] Elasticsearch GET itemid %d from %d to %d, count %d", itemid, (int)start, (int)end, (int)count);
+ }
With this patch I managed to decrease delay from 25-40 minutes to 9-10. This is not so good as I want too but I still don't exactly know what are the reasons of this delay. May be the server waiting on something else or value cache is only a part of problem, but the patch is exactly reduces exec delay.
|
|
Zabbix server should search in Elasticsearch instead of getting values from Elasticsearch and searching itself.
There is following request:
It will read all values in 130 seconds which can be many, store them in cache and search the cache, unfortunately it's not good approach for Zabbix server, it should instead provide a way to search in elasticsearch if there are such values, is it possible to test if moving such checks to http agent and queuing through elastic resolve the issue ?
Does moving from triggers to calculated items and then creating triggers to calculated items resolve issue ? As calculated items are not calculated by history syncer buy triggers are so it blocks.
How long periods are in nodata triggers ?
Currently it seems that there are trigger expressions that are slow and it’s best to identify those before proceeding with the fix.
For example trigger for itemid:2484077
Please provide new diagonfo after restart(with newer version) and expressions that use those items, if possible also enable profiling, with prof_enable command for history syncer and provide results please.
Also please see ZBX-24264
|
|
Confirmed, for MySQL and PostgreSQL there are lower bounds when performing count based request, this should also be the case for Elasticsearch, check for hour first then 12 hours, day, week, month, but bounds should be limited by global history storage period.
Current example:
{
"size": 3,
"sort": [
{
"clock": {
"order": "desc"
}
}
],
"query": {
"bool": {
"must": [
{
"match": {
"itemid": 48297
}
}
],
"filter": [
{
"range": {
"clock": {
"lte": 1734348380
}
}
}
]
}
}
}
Expected:
{
"size": 3,
"sort": [
{
"clock": {
"order": "desc"
}
}
],
"query": {
"bool": {
"must": [
{
"match": {
"itemid": 48297
}
}
],
"filter": [
{
"range": {
"clock": {
"gte": 17343480200,
"lte": 17343483800
}
}
}
]
}
}
}
|
|
Thanks for your response. So let me explain in order.
Have I understood your explanations correctly?
1. LOG item must be replaced by http agent item, that works directly with Elasticsearch because this type of items can provide unexpected amount of data?
2. Triggers with the expressions kind of as in my example are processing by history syncer and that is the cause of performance issues? Those triggers must be replaced by calculated item and triggers with simple expression?
3. Triggers with nodata items has a periods, that not higher than 20 minutes. Also during last several months I've updated to server version 7.0.1 and it has the same behavior.
4. Trigger expression for itemid:2484077 is
last(/host_xxx/vfs.file.exists[{$MAILBOX}],#3)=1 and last(/host_xxx/vfs.file.size[{$MAILBOX}],#3)>0 and (now()-last(/host_xxx/vfs.file.time[{$MAILBOX}]))<604799
I have a lot of this kind of triggers. On the next server update(to last 7.0.x version) I'll try to gather debug info you requested.
5. Are you confirm the issue with Elasticsearch query bounds in history requests? Is the global history storage period works as when the history is in the Elasticsearch?
|
|
Yes, I confirm the same that you have mentioned in comment with a patch, we will get back to you when a solution is implemented, we will very much appreciate if you will try it and confirm if this improvement helps or resolves the issue.
|
|
Thank you! Ill wait for news and update to version with patch and check this
|
|
Fixed in pull request feature/ZBX-24549-7.0-2
|
|
(1) [D] When Elasticsearch is used then range queries when retrieving values from database will be limited by timestamp of data storage period.
|
|
(2) [D] LogSlowQueries can be used to check slow queries to Elasticsearch database
|
|
If there is test instance then please try running with ZBX-24549-7.0-final.diff please see if there are slow query reported in log, controlled by LogSlowQueries configuration parameter. please see if there are slow query reported in log, controlled by LogSlowQueries configuration parameter.
|
|
Also please see ZBX-25777 and ZBX-21481
|
|
Fixed in:
|
|
https://www.reddit.com/r/zabbix/comments/1ie5zcb/zabbix_value_cache_under_70/
after installing version 7.0.9 there is a problem with memory leak in the cache. maybe it's related to this topic.
|
|
Was it possible to check if latest version resolve issues artem.kh ?
|
|
Updated documentation:
- Elasticsearch setup: 7.0, 7.2, 7.4 (added troubleshooting step with LogSlowQueries and note about range queries).
|
Generated at Tue Aug 05 00:11:37 EEST 2025 using Jira 9.12.4#9120004-sha1:625303b708afdb767e17cb2838290c41888e9ff0.
