|
Original bug report:
ZBXNEXT-3089
|
|
Test results
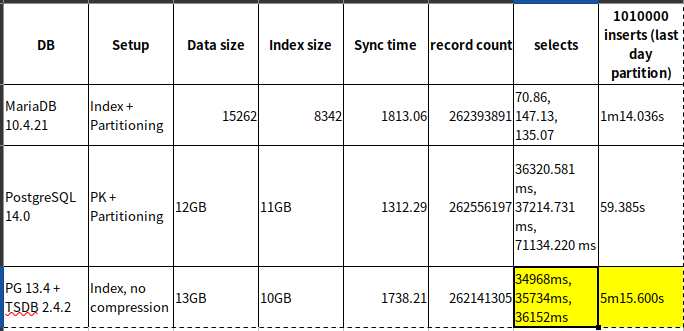
| DB |
Setup |
Data size |
Index size |
Sync time |
record count |
selects |
1010000 inserts (last day partition) |
| MariaDB 10.4.21 |
Index + Partitioning |
15262 |
8342 |
1813.06 |
262393891 |
70.86, 147.13, 135.07 |
1m14.036s |
| MariaDB 10.4.21 |
PK + Partitioning |
14618 |
0 |
1330.55 |
262391437 |
56.59, 113.18, 109.13 |
1m9.996s |
| MariaDB 10.6.4 |
Index + Partitioning |
15184 |
8336 |
1802.19 |
262392533 |
69.33, 144.17, 129.78 |
1m13.141s |
| MariaDB 10.6.4 |
PK + Partitioning |
14620 |
0 |
1317.32 |
262392217 |
55.34, 105.51, 110.97 |
1m9.083s |
| Mysql 8.0.26 |
Index + Partitioning |
15667 |
8317 |
2193.11 |
262393746 |
79.37, 162.44, 143.60 |
1m27.083s |
| Mysql 8.0.26 |
PK + Partitioning |
14856 |
0 |
1798.21 |
262398902 |
69.53, 139.64, 118.36 |
1m24.426s |
| MariaDB 10.4 |
Index w/o Partitioning |
15512 |
6906 |
1873.41 |
262394526 |
84.13, 195.46, 169.24 |
1m10.562s |
| MariaDB 10.4 |
PK w/o Partitioning |
13688.97 |
0 |
1341.2 |
262394469 |
82.79, 176.25, 157.73 |
1m7.387s |
| PostgreSQL 14.0 |
Index + Partitioning |
24GB |
7.3GB |
1373.16 |
262325176 |
35550.794 ms, 36656.102 ms, 71350.073 ms |
58.765s |
| PostgreSQL 14.0 |
PK + Partitioning |
12GB |
11GB |
1312.29 |
262556197 |
36320.581 ms, 37214.731 ms, 71134.220 ms |
59.385s |
| PG 13.4 + TSDB 2.4.2 |
Index, no compression |
13GB |
10GB |
1738.21 |
262141305 |
34968ms, 35734ms, 36152ms |
5m15.600s |
| PG 13.4 + TSDB 2.4.2 |
PK, no compression |
13GB |
14GB |
1717.43 |
262155334 |
37345ms, 38572ms, 38703ms |
5m43.560s |
Data was initially sent to the proxy (with server being down), and then total history sync time was collected.
Selects used:
Inserts contained exactly the same queries for each db test (resembling normal history data, not random).
Queries were executed without SQL_NO_CACHE.
In case when partitioning was used, tables were partitioned by clock, one partition per day (24 hours / 86400 seconds). Data was resembling normal history data, without itemid-clock-ns duplicates.
Primary key was configured as follows:
Relative differences between same db versions should be taken into account.
|
|
Available in versions:
|
|
So if I understand that correctly, when I update our Zabbix server that exists since 2.0, from 5.4 to 6.0, nothing will change, right?
|
|
That is right starko, history tables can only be upgraded manually to use primary keys.
|
|
What impact does that have for all customers, who upgrade to 6.0 instead of re-installing? I'm no DBA, but if I read this table correctly, it would become a little bit faster, but not tremendously?
(Debian 11 bullseye, MariaDB 10.5, no Partitioning)
|
|
starko , Zabbix will not switch to primary keys automatically when upgrading from earlier releases. It should be done manually. If you install a fresh Zabbix 6.0 then the DB schema will have primary keys for historical tables. Depending on DB engine you may expect better performance and lower (up-to 30%) disk usage.
|
|
alexei Thank you very much for the clarification!
Last time something fundamentally changed in the DB schema, the switch to new default charset utf8 and collation utf8_bin for MySQL & MariaDB, the Zabbix server database upgrade process didn't touch the schema, but Zabbix company provided a conversion script, via ZBX-17357 which resulted in the following documentation article, which was extremely useful to us: https://www.zabbix.com/documentation/current/manual/appendix/install/db_charset_coll
Will there be a similar conversion script, for customers who want to follow the primary key schema change, after they've upgraded to 6.0 LTS?
|
|
starko , I should have mentioned it earlier, the database conversion scripts will be provided for all support DB engines. It will be part of the official documentation and/or release notes.
|
|
Wow, that's great news, thank you very much!
|
|
@Alexei Very interesting topic! Do you think we can have more details about these numbers:

It seems huge difference for Postgres+TSDB for ingestion time and MariaDB seems more fast for "select" compared to Postgres (without TSDB).
Thanks so much
|
|
dimitri.bellini , take these benchmarks with a grain of salt as the configuration of the databases and hardware was different.
|
|
@Alexei ok thanks 
|
|
So what is the current recommendation for operating larger Zabbix installations?
Postgres+TSDB or MySQL?
Why would you run these tests on different hardware/different configuration? To give a bad impression for Postgres+TSDB?
When my colleague saw these results he bashed my for migrating away from MySQL to TimeScaleDB last year with huge pain points (https://support.zabbix.com/browse/ZBX-16347?focusedCommentId=416975&page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel#comment-416975 ...) .
Sometimes it seems to me your "test environment" while developing consists of monitoring the laptop running your zabbix container and the switch port in front of it.
|
|
rstumbaum, I can assure you that we have a whole range of test platforms available starting from beefy bare metal servers to the whole range of AWS/GCP/Azure server instances and K8S clusters. The test we ran here had only one goal, i.e. discover any drawbacks of having primary keys as well as identify possible benefits. These tests were not aimed to benchmarking of the performance of various storage engines.
There is no silver bullet when it comes to selection of an ideal database. It always depends on your priorities (like speed vs maintainability vs HA options etc).
|
|
Available in versions:
Documentation updated:
|
|
The primary keys upgrade guide does not mention removing the CSV files.
Also, will this work for users that use partitions? If not, will we provide any help to them?
|
|
In 3 Database upgrade to primary keys, section Improving performance,
both external links (MySQL 5.7, MySQL 8.0) are pointing to "Not Found" content.
|
|
Also, "3 Database upgrade to primary keys" document has no mention to backup the database first.
|
|
markfree, the issues you mentioned have been fixed. Thank you.
|
Generated at Fri Apr 11 12:25:30 EEST 2025 using Jira 9.12.4#9120004-sha1:625303b708afdb767e17cb2838290c41888e9ff0.