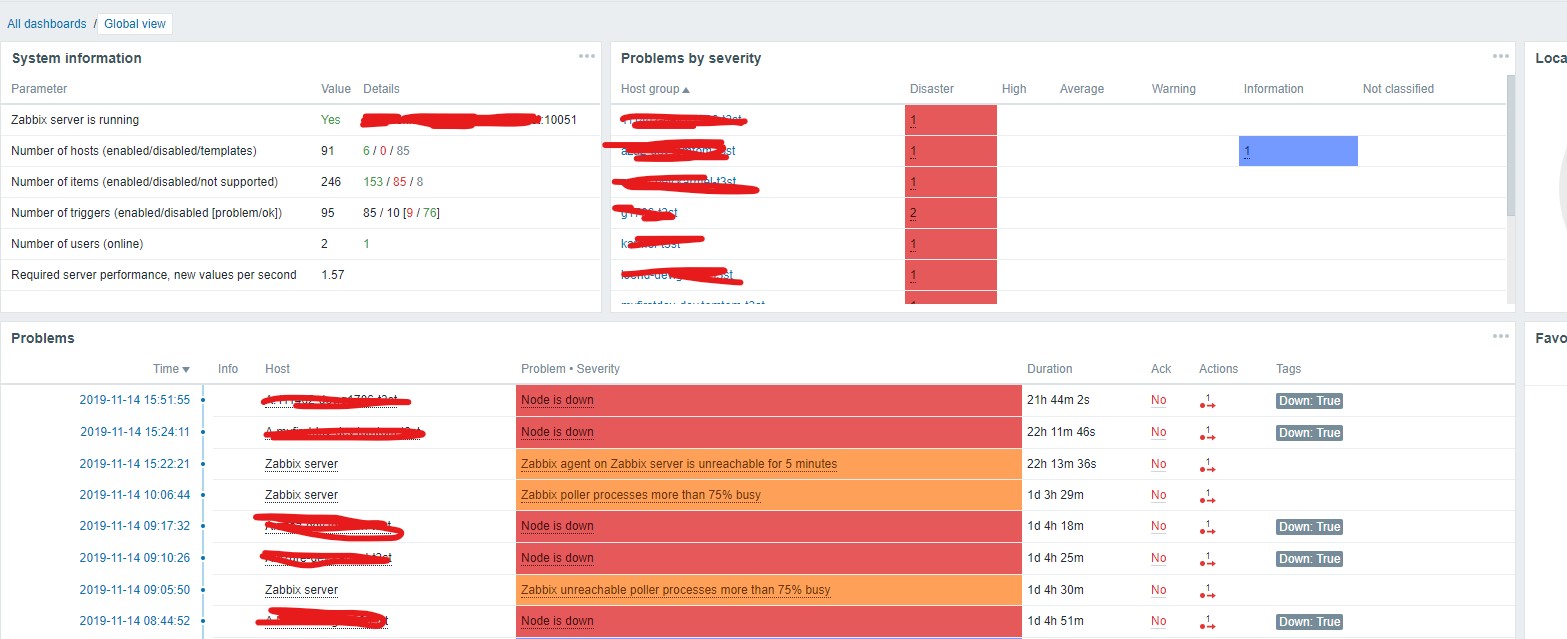
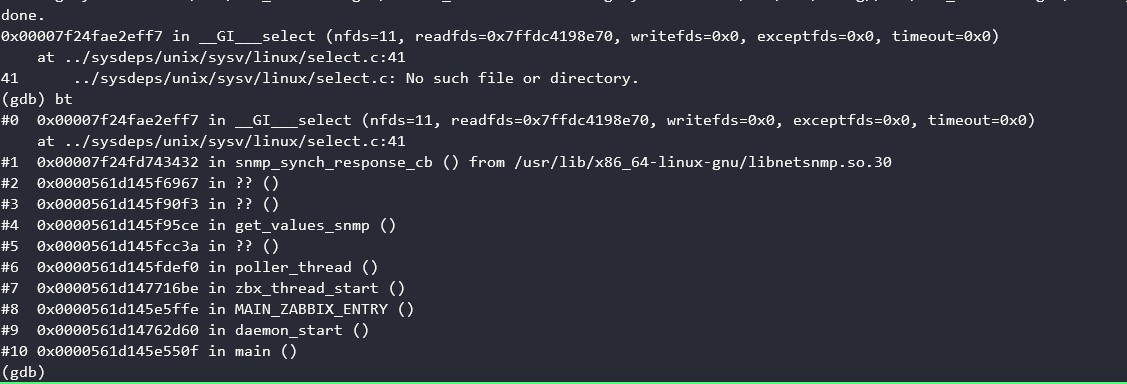
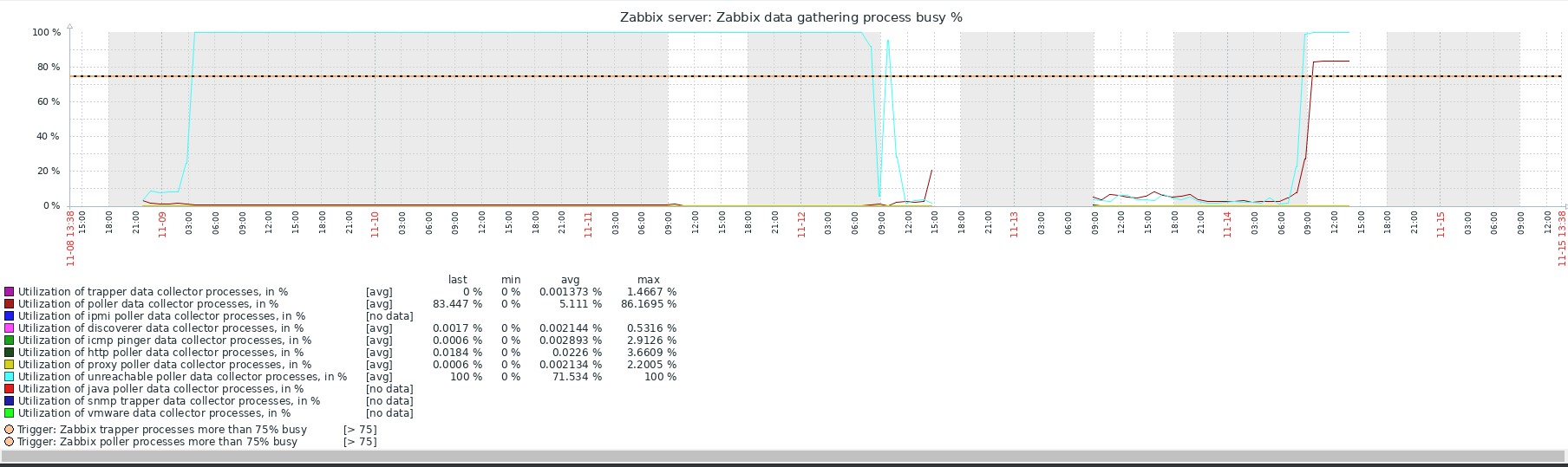
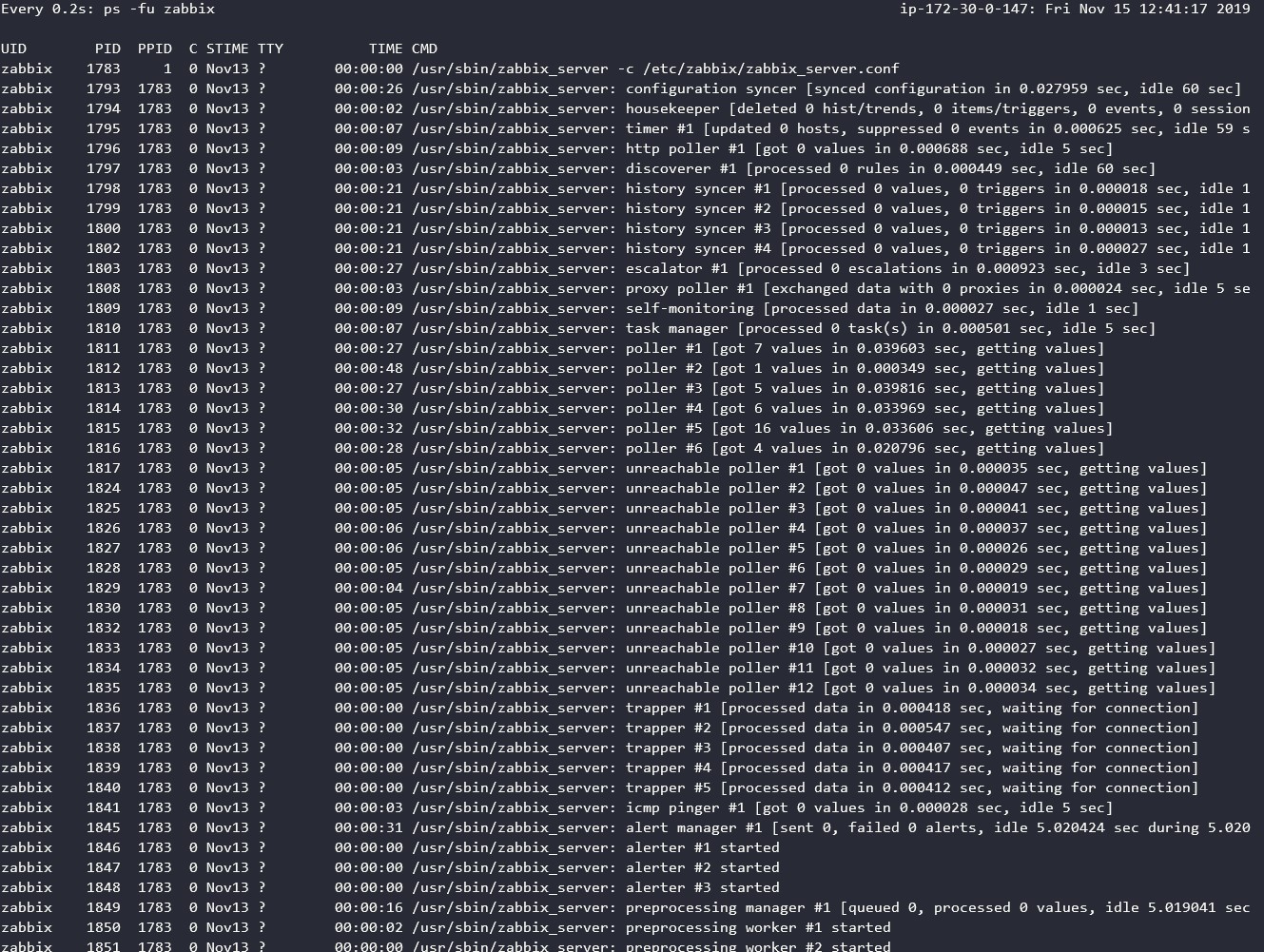
It acted the same in version 3.4 too. Tried to upgrade but it did not help.
Steps to reproduce:
- Setup few SNMPv3 hosts
- After some time (few to several hours) notice all pollers (both unreachable and regular ones) are busy. Hosts are supposedly down.
Result:
see "Annotation 2019-11-15 133726.jpg"
see "graph_pollers_busy.jpg"
Please bear with me...
I checked few things and this is what I found out.
First I went to see PS output and noticed that poller and unreachable pollers descriptions do not update at all. See 'ps-pollers-getting-values.jpg'.
Tried strace main zabbix process (with child processes), but there was no action there too. See 'strace-main-zabbix-server-with-child-processes-stuck.jpg'
Then went to strace the pollers. All of them were stuck on select call (tried waiting for a bit) without timeout reading from descriptor 10 - a UDP socket. See 'strace-poller-process-stuck-on-select.jpg' and 'lsof-udp-fd-10.jpg'
What's it doing? Here's a backtrace from gdb - see "gdb-poller-process-bt.jpg"
In zabbix sources it said NETSNMP has its own timeout values, I checked there and saw this piece of code (version 5.4.4) - notice / block without timeout / comment:
int snmp_synch_response_cb(netsnmp_session * ss, netsnmp_pdu *pdu, netsnmp_pdu **response, snmp_callback pcb) { struct synch_state lstate, *state; snmp_callback cbsav; void *cbmagsav; int numfds, count; fd_set fdset; struct timeval timeout, *tvp; int block; memset((void *) &lstate, 0, sizeof(lstate)); state = &lstate; cbsav = ss->callback; cbmagsav = ss->callback_magic; ss->callback = pcb; ss->callback_magic = (void *) state; if ((state->reqid = snmp_send(ss, pdu)) == 0) { snmp_free_pdu(pdu); state->status = STAT_ERROR; } else state->waiting = 1; while (state->waiting) { numfds = 0; FD_ZERO(&fdset); block = NETSNMP_SNMPBLOCK; tvp = &timeout; timerclear(tvp); snmp_select_info(&numfds, &fdset, tvp, &block); if (block == 1) tvp = NULL; /* block without timeout */ count = select(numfds, &fdset, 0, 0, tvp); if (count > 0) { snmp_read(&fdset); } else { switch (count) { case 0: snmp_timeout(); break; case -1: if (errno == EINTR) { continue; } else { snmp_errno = SNMPERR_GENERR; /*MTCRITICAL_RESOURCE */ /* * CAUTION! if another thread closed the socket(s) * waited on here, the session structure was freed. * It would be nice, but we can't rely on the pointer. * ss->s_snmp_errno = SNMPERR_GENERR; * ss->s_errno = errno; */ snmp_set_detail(strerror(errno)); } /* * FALLTHRU */ default: state->status = STAT_ERROR; state->waiting = 0; } } if ( ss->flags & SNMP_FLAGS_RESP_CALLBACK ) { void (*cb)(void); cb = ss->myvoid; cb(); /* Used to invoke 'netsnmp_check_outstanding_agent_requests();' on internal AgentX queries. */ } } *response = state->pdu; ss->callback = cbsav; ss->callback_magic = cbmagsav; return state->status; }
So all my pollers seem to be stuck waiting forever for a response from UDP socket.
After server restart it goes back to normal.