-
Type:
Problem report
-
Resolution: Duplicate
-
Priority:
 Major
Major
-
None
-
Affects Version/s: 5.0.35, 6.0.18, 6.4.3
-
Component/s: Server (S)
-
Environment:Mysql 8.0.32
zabbix 6.4.2
Zabbix Team -
I recently encountered an issue where the LLD queue would not ever reach 0. It turns out that something within the high performance computing application I monitor started producing tens of thousands of unique metrics. The way this Zabbix instance is configured is to use low level discovery to create and update these particular metrics (itemprototypes, triggerprototypes, etc). Whether these metrics are valuable or not is still to be determined, but I think we need to presume that they are useful to somebody.
With that, I decided to run some tests in a development environment to reproduce the issue, and grab some data points to share with you.
TEST SCENARIO:
- Create 1 host and either link to a template or create a discovery rule with a Trapper type.
- Create 1 itemprototype that is part of the same LLD Trapper rule
- run a script to batch up 2500 key:value pairs of {#MACRO}: <unique_value> pairs. Note, in the production system this is pretty comparable to what we observed: every metric that was produced each metric interval (600 second intervals) had some subset of the many thousands of metrics. It just depended on what work was done during that 600 second interval. Here is the script I wrote to do this:
#!/usr/bin/env python import sys, subprocess, json from pyzabbix import ZabbixAPI ITEMS = int(sys.argv[1]) zapi = ZabbixAPI("http://localhost/zabbix") zapi.login("Admin", "zabbix") caselist = list() for n in range(ITEMS, ITEMS+2500): caselist.append({"{#MACRO}": f"CASE{n}"}) caselist = json.dumps(caselist) cmd = f"zabbix_sender -z 127.0.0.1 -s host0 -k lldone -o '{caselist}'" l = subprocess.Popen(cmd, shell = True, stdout=subprocess.PIPE)
Then, in a bash for-loop, I just called the script 41 times in an attempt to create over 100000 itemprototypes.
[root@localhost ~]# for n in 0 2500 5000 7500 10000 12500 15000 17500 20000 22500 25000 27500 30000 32500 35000 37500 40000 42500 45000 47500 50000 52500 55000 57500 60000 62500 65000 67500 70000 72500 75000 77500 80000 82500 85000 87500 90000 92500 95000 97500 100000; do python3.9 lld_worker_stress_test.py $n; done
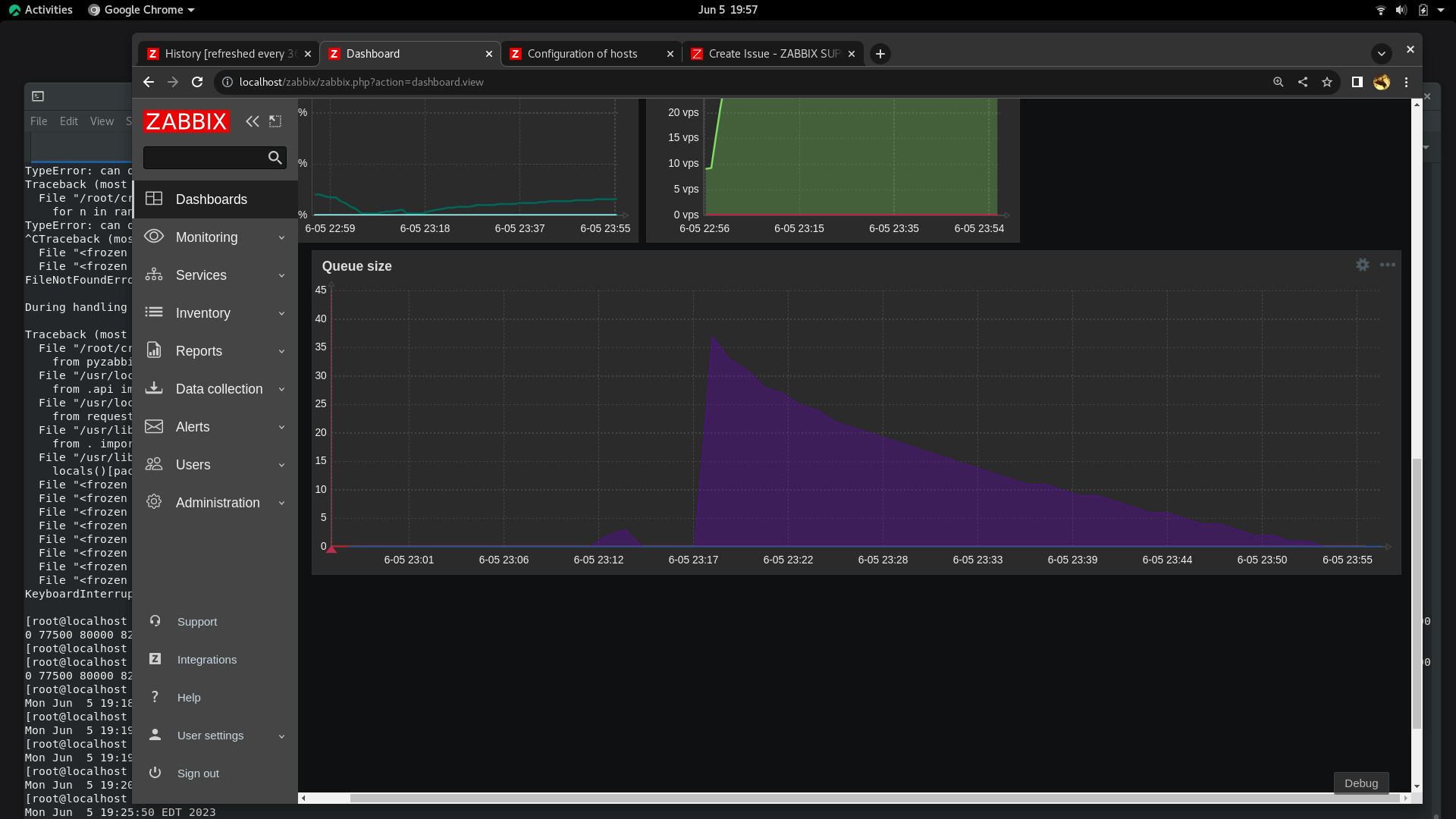
The result is that it took approximately 35 minutes to work through all 41 of the LLD rules on my lab machine. The first 10000 - 20000 items were created in about 2 minutes, but as more items were created the lld worker worked through each subsequent LLD rule slower than the previous. I've attached a screenshot of the LLD queue showing the asymptotic curve in performance of the lld worker.
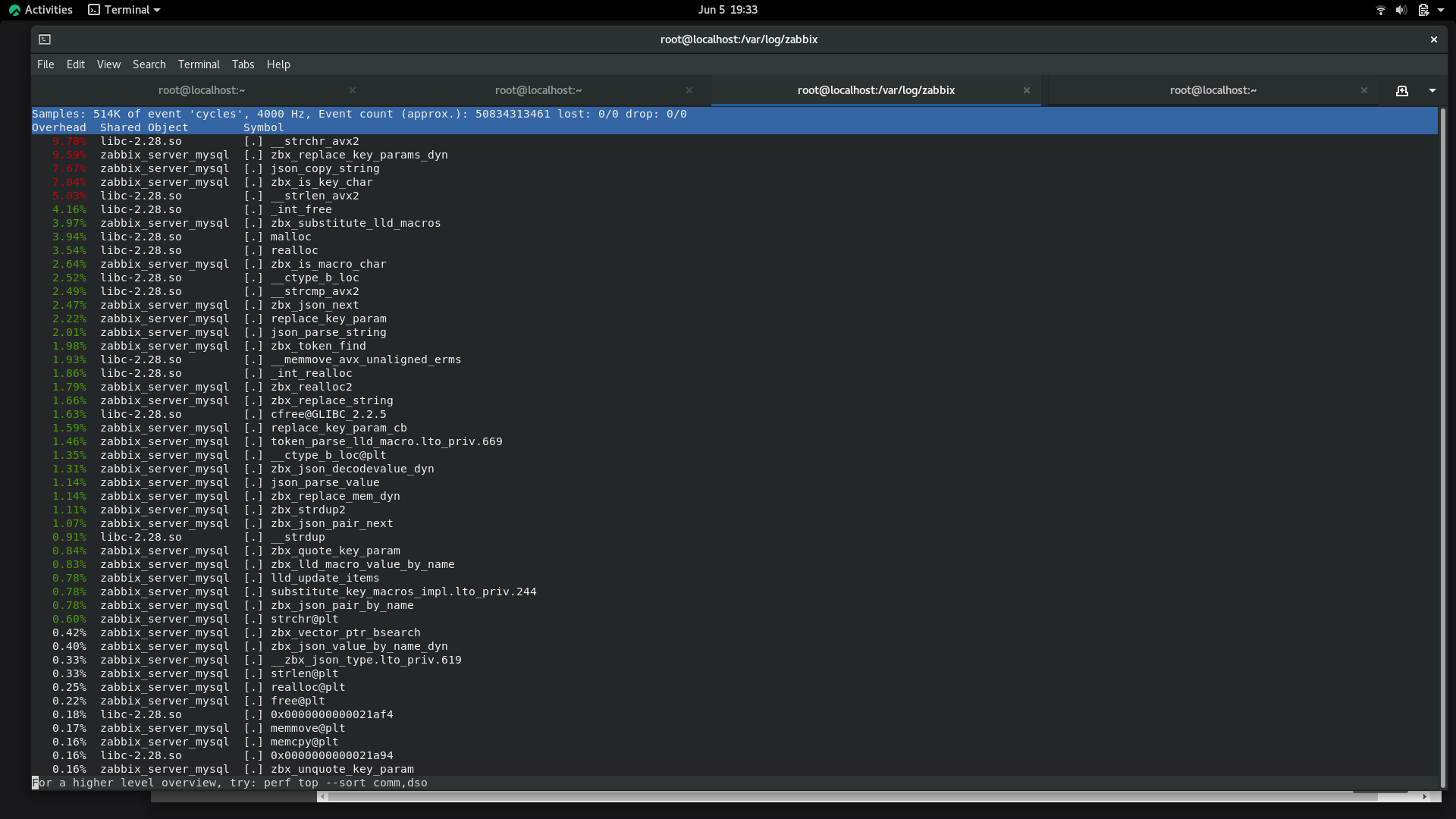
Also, I attached screenshot of perf-top against the lld worker that was doing the work, to show which calls were the busiest.
In another test I broke up the 100000 items across different LLD rules and the time to completion was much more linear, which demonstrates that internally the lld code is working within an LLD rule comparing items and triggers within the parent rule.
I also noticed that only 1 lld worker of the 10 workers I have pre-forked did all the work. I'm guessing the manager might hash the work so that work for a given host only goes to one lld worker to prevent duplication in the database.
My question is, has there ever been a Zabbix instance that had this number of metrics being created for one LLD rule on one host before? Do you expect the lld worker to gradually become slower as more items are created within an LLD rule? Do we expect Zabbix to be able to handle this kind of load? Looking at the code, it would appear that you select all values from the database first and iterate through the results, so it would seem to be expected that the worker would get slower as there is more and more to iterate through. Or, was Zabbix never designed to scale like this? If instead I created 10 hosts, each with 10000 items, the 10 lld workers would have completed everything in about 2 minutes, so Zabbix definitely scales very well when there are many hosts with fewer items, but since all metrics are aligned to hosts it doesn't make sense to try and split these thousands of items across synthetic hostnames.
Let me know if I can provide any additional info. It'd be good if we can find some optimizations for this if at all possible.
- duplicates
-
ZBXNEXT-9233 Increasing the limit for Zabbix dependent items from 29999 to a higher value
-
- Closed
-