-
Type:
Problem report
-
Resolution: Fixed
-
Priority:
 Critical
Critical
-
Affects Version/s: 6.4.6
-
Component/s: Server (S)
-
None
-
Environment:Zabbix server and proxies running on containers (podman).
-
S2401-1, S24-W6/7, S24-W8/9
-
0.5
Hi,
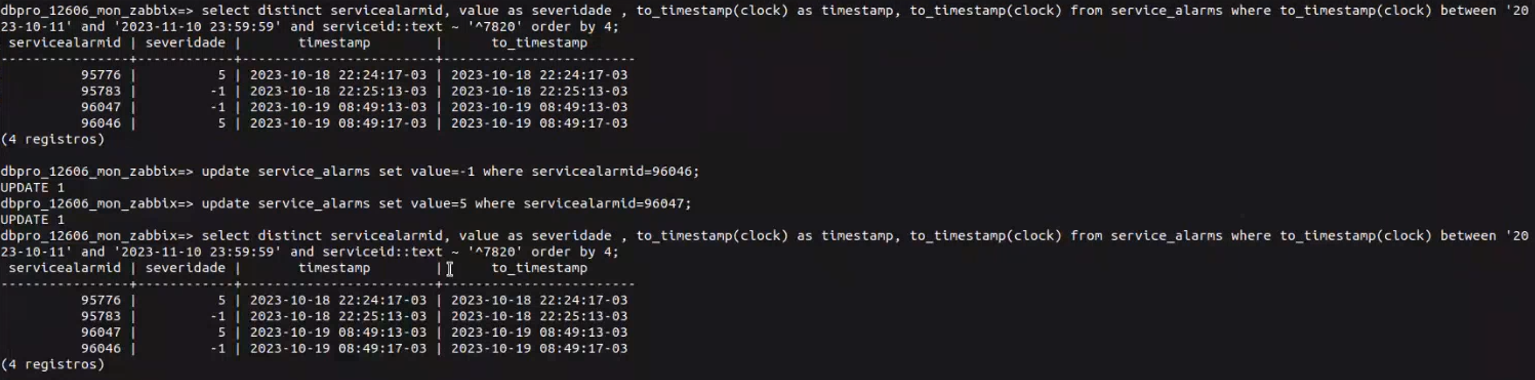
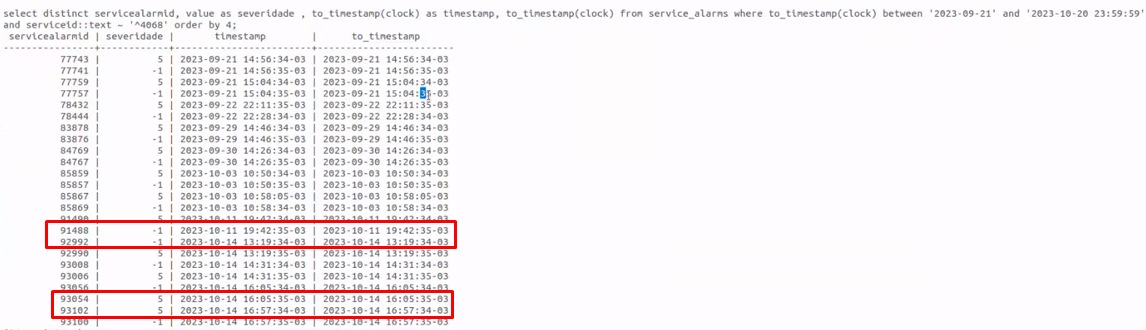
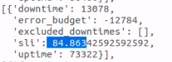
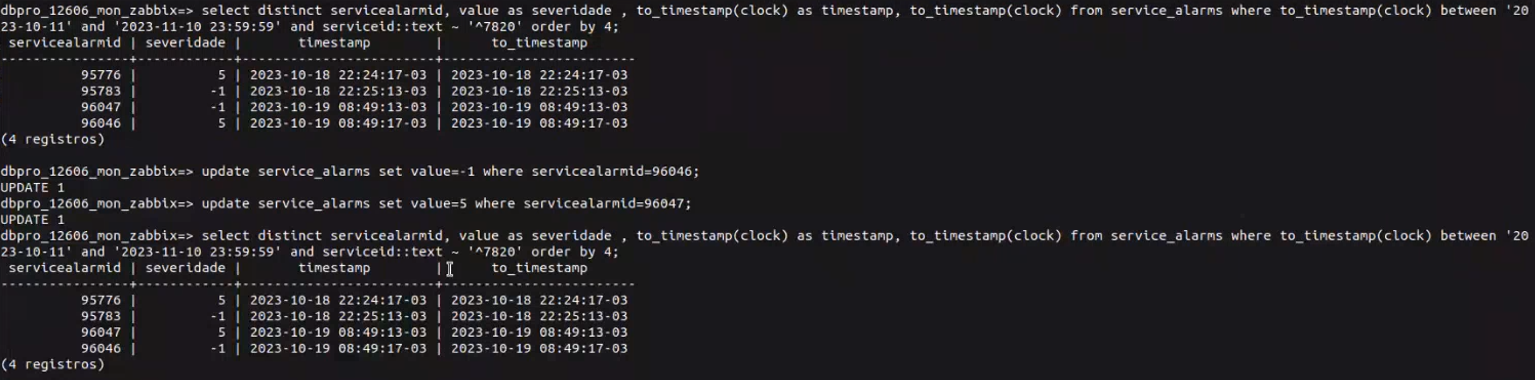
We are dealing with an issue related to the SLA calculation been affected by entries that seems to be wrongly inserted on the Database. As you can see on the screenshot below, the Service (with id 4668) is changing the value from 5 (Disaster) to -1 (Ok), but on the highlighted portion of the screenshot you can see that the serverity is change from -1 to -1, and also from 5 to 5. This is directly affecting the calculation of the SLA for our customers.
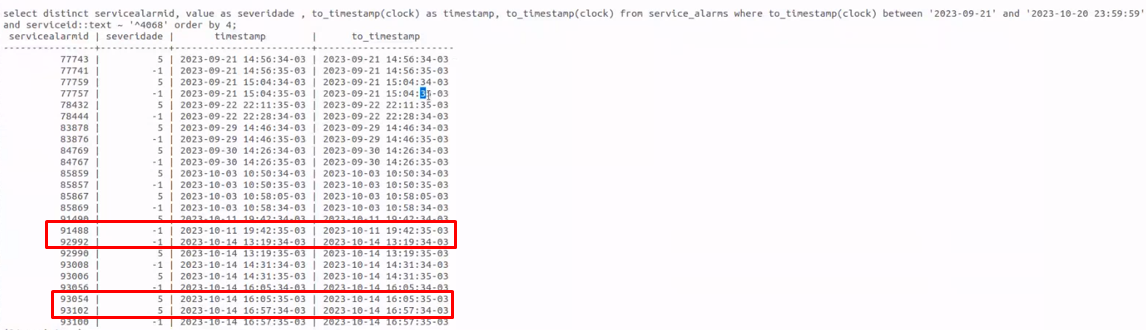
Currently we are proceeding with the manual update and fixing everything related to it, which is quite troublesome, for if we insert one single wrong information, the outcome can be a problem.
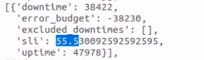
As evidence that this is causing the SLI of our reports to be affected, I have performed some API requests to demonstrate:
Before update / After update
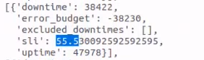
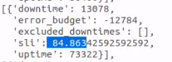
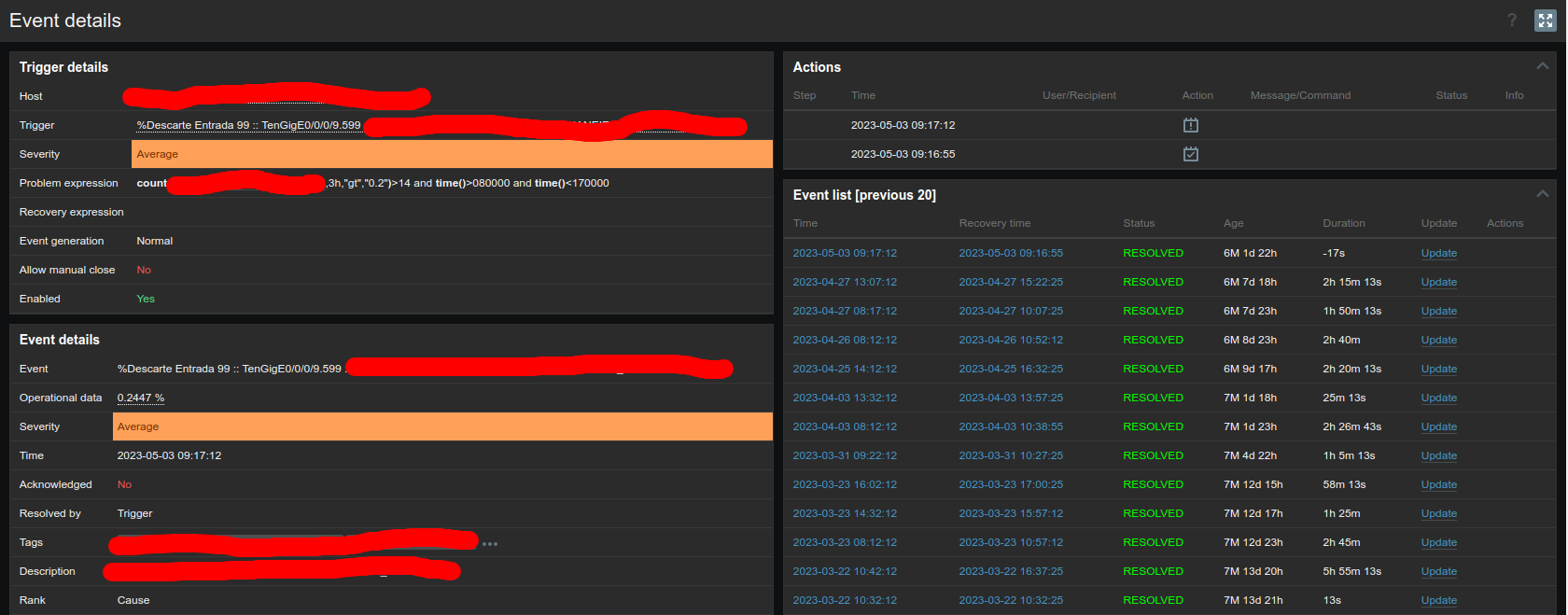
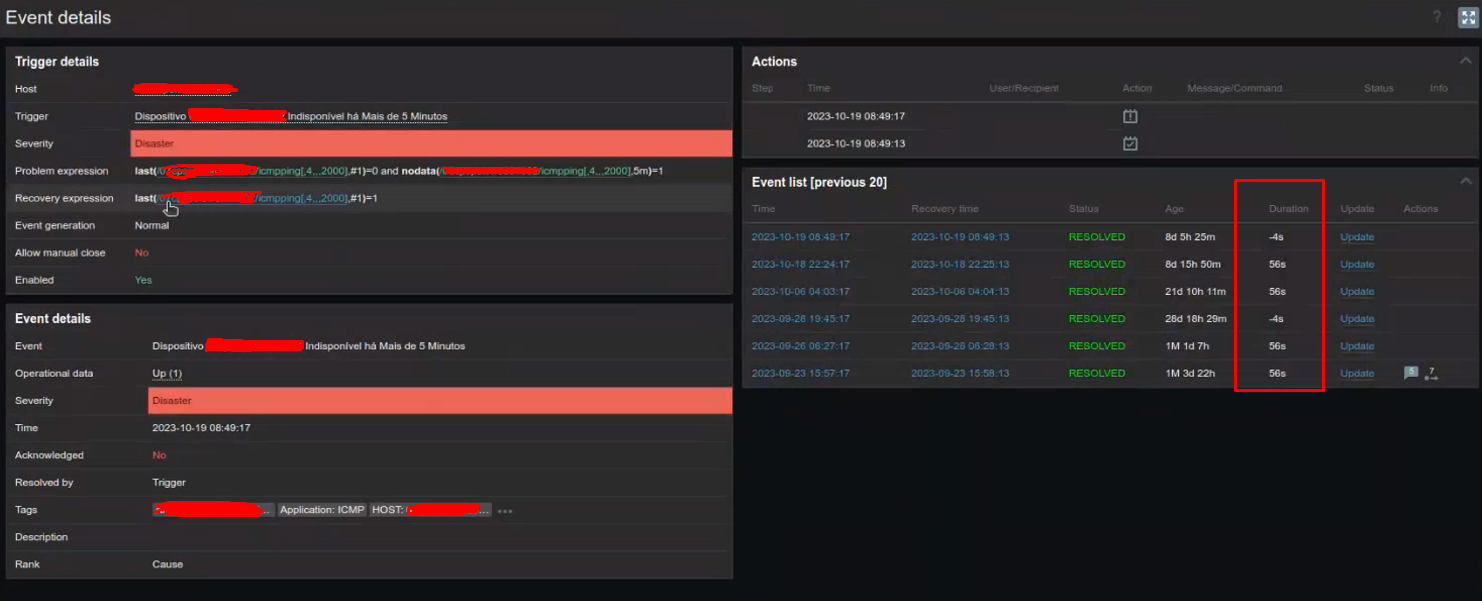
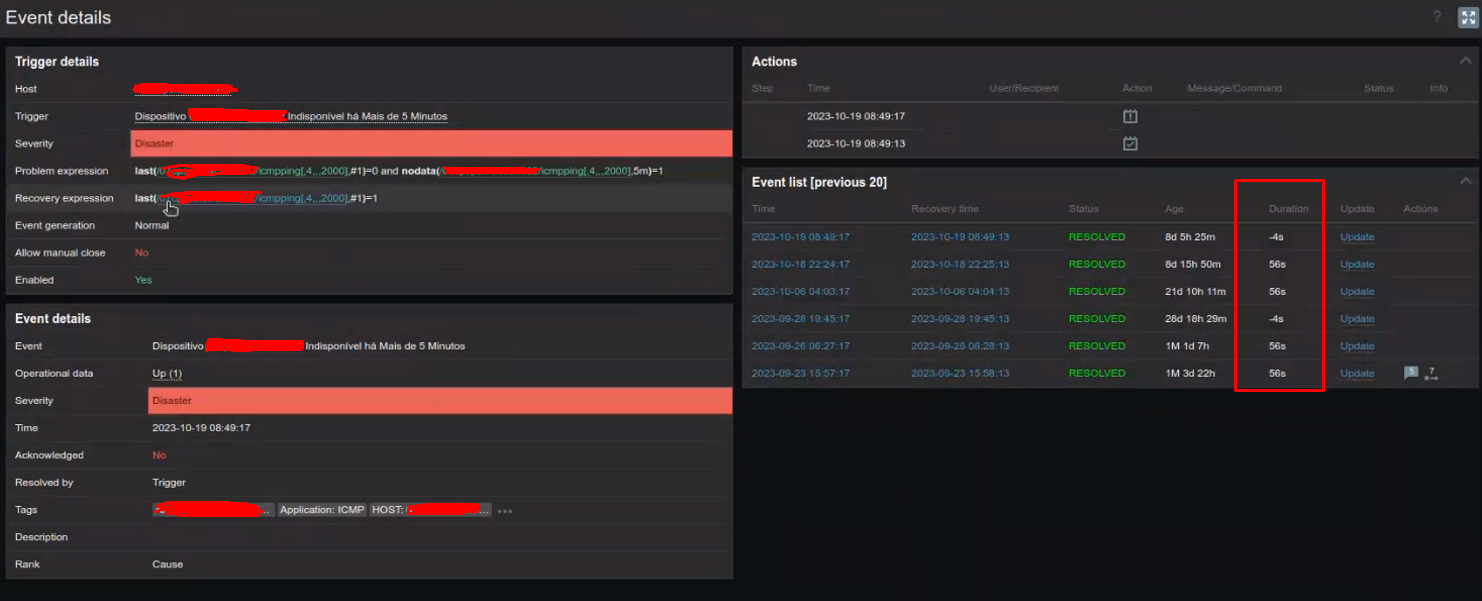
After investigating a few, we checked that this scenario is being affected by a "Negative duration" scenario. I don't believe it is a coincidence since it happens numerous times on the day.
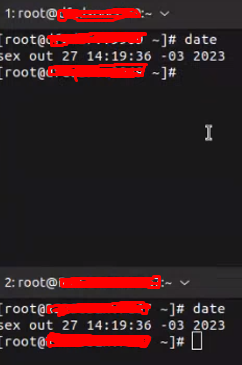
As for the negative event occurrence, we have checked over and over, but it doesn't seem to be cause by unsynced time between Server and Proxy, for example. We have a NTP server that is taking care of our whole network and all the time we check, it is synced up.
The type of items related to this are always ICMP ping items.
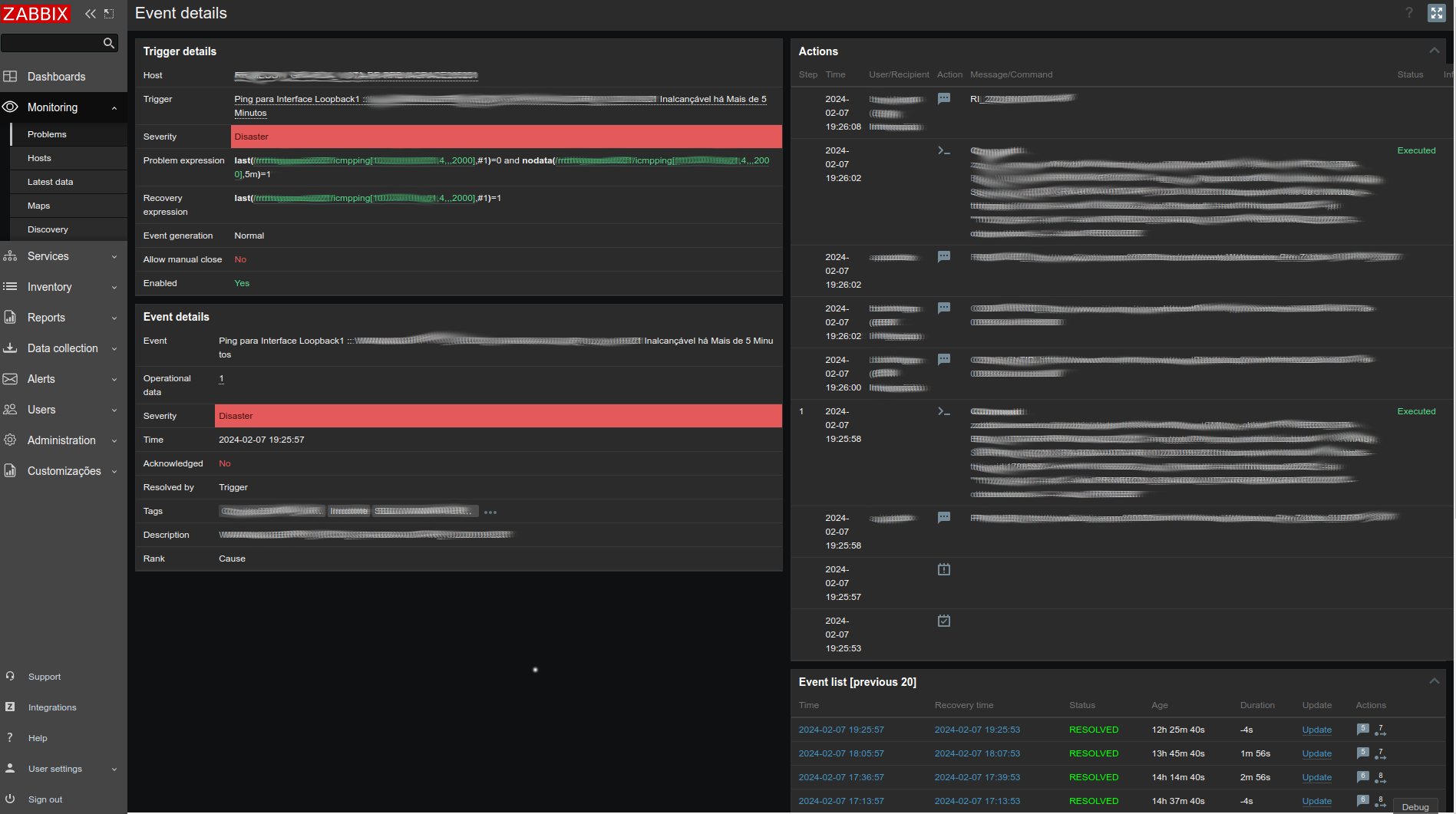
I can show below an example of the ocurrence:
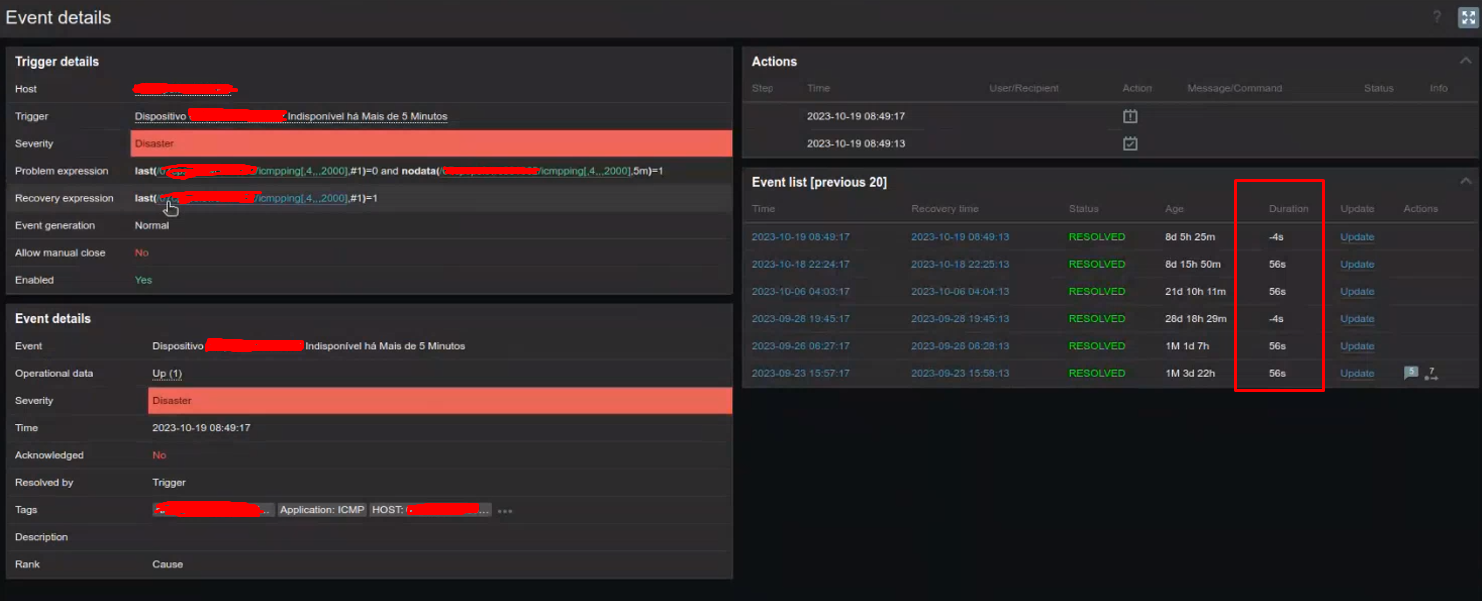
Time between hosts synced:
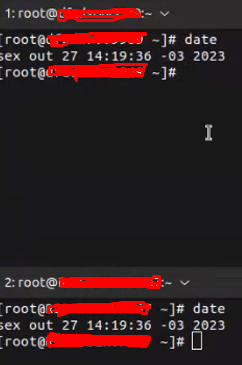
As they run in containers, we also checked the possibility of having unsynced time between them as well, and everything is fine.
This behavior seems be going against what is defined on the Documentation:
NOTE: Negative problem duration is not affecting SLA calculation or Availability report of a particular trigger in any way; it neither reduces nor expands problem time.
As it is indeed affecting the our SLAs report.
As a workaround, as already mentioned, we are having to apply changes manually to obtain the correct SLI and SLA report.
**
- depends on
-
-

- Closed
-
