-
Type:
Incident report
-
Resolution: Fixed
-
Priority:
 Major
Major
-
Affects Version/s: 2.2.3
-
Component/s: Server (S)
-
None
-
Environment:CentOS 6.5 x86_64
Ever since we upgraded from 2.0 to 2.2.x, we get random 'server is unreachable' triggers being activated, and resolved a minute or so later. This happens 1 or 2 times every day ( and night ), with no immediate cause.
Here are the agent.ping items from the time the alert is triggered:
2014.Apr.16 03:36:58 Up (1)
2014.Apr.16 03:35:28 Up (1)
2014.Apr.16 03:33:58 Up (1)
2014.Apr.16 03:32:28 Up (1)
2014.Apr.16 03:32:16 Up (1)
2014.Apr.16 03:21:58 Up (1)
2014.Apr.16 03:20:29 Up (1)
2014.Apr.16 03:18:58 Up (1)
2014.Apr.16 03:17:28 Up (1)
2014.Apr.16 03:15:58 Up (1)
As you can see there is a 10 minute gap in items. We have set DebugLevel to 4 on both server and agent, and that showed us that the server never creates/asks those items, making it seem like a server issue, not an agent one.
A bit more info about our environment:
Number of hosts (monitored/not monitored/templates) 444 384 / 7 / 53
Number of items (monitored/disabled/not supported) 26142 24525 / 513 / 1104
Number of triggers (enabled/disabled) [problem/ok] 5406 5401 / 5 [51 / 5350]
Required server performance, new values per second 144.63 -
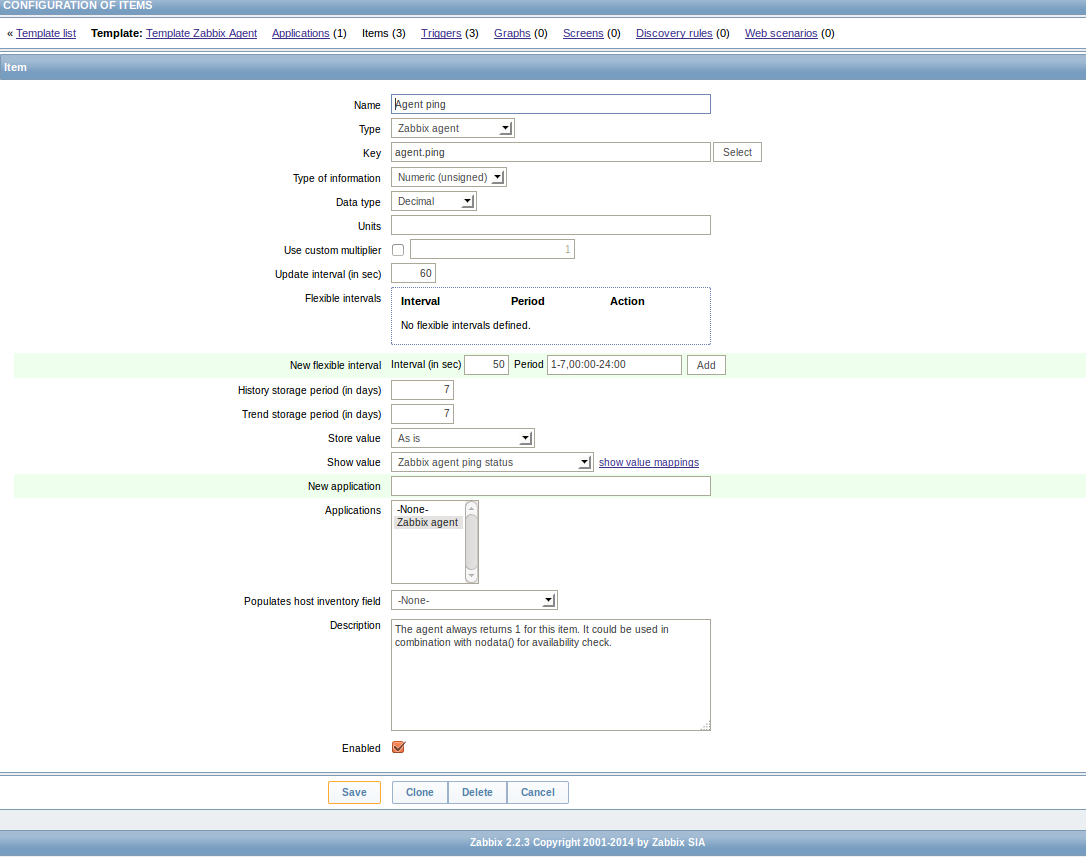
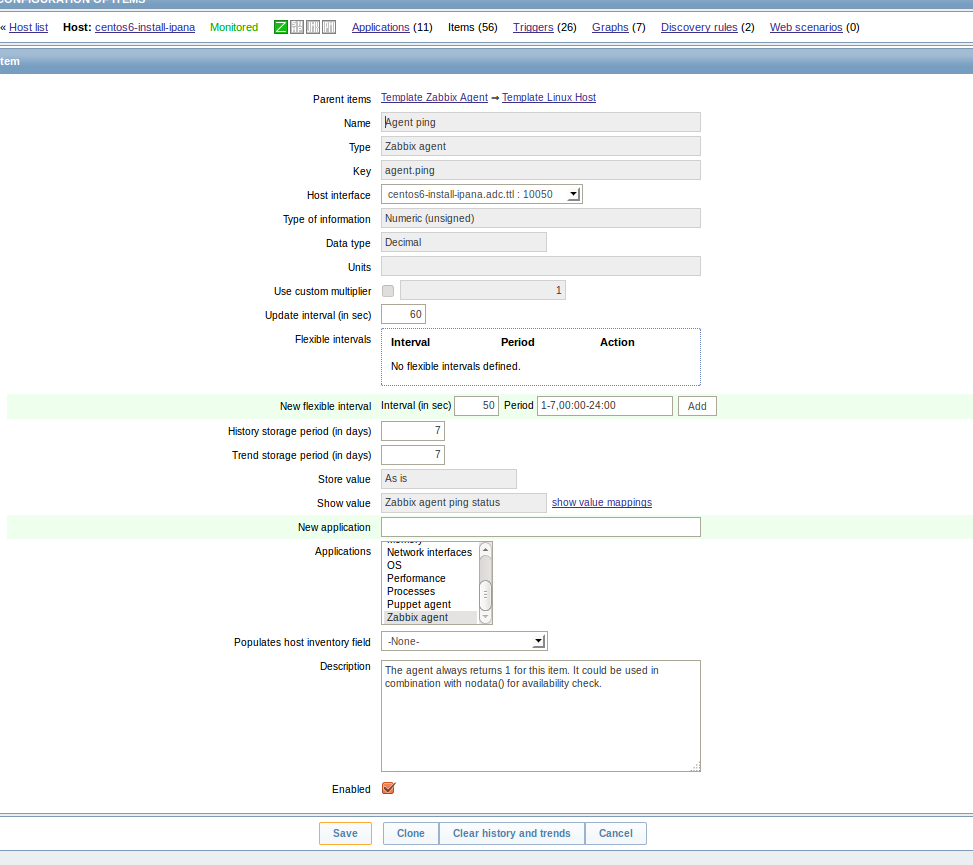
Item: Agent ping Triggers (2) agent.ping 60 7 7 Zabbix agent Zabbix agent
Trigger:
=1
PS: Our template has an update interval of 60, while all hosts put it at 90, i guess that's worthy of another bug report.
Internal Zabbix server items are quite idle, with busy poller % for example being around 10-15%. It was 20-25 %, but we increased pollers from 5 to 12 in the hopes of alleviating this problem. It didnt help.
Anything else we can provide?

- is duplicated by
-
-

- Closed
-