-
Type:
Incident report
-
Resolution: Won't fix
-
Priority:
 Trivial
Trivial
-
None
-
Affects Version/s: 2.4.1
-
Component/s: Agent (G), Server (S)
-
None
-
Environment:Server: CentOS6
Client: Windows Server 2008 R2
Both are Virtualized on VMWare
Originally reported here: https://www.zabbix.com/forum/showthread.php?s=4937fdde6a8a7dac44e43318c9dd129d&p=156654
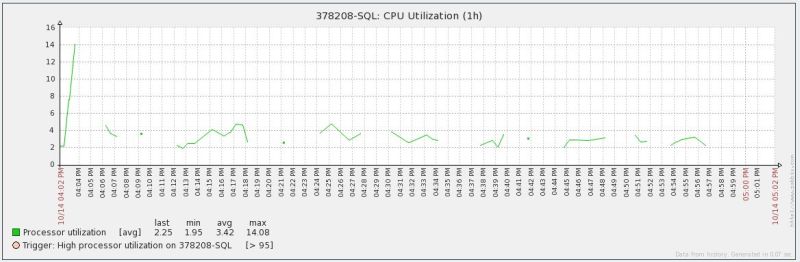
So, this is an issue I have run into in both old versions of Zabbix (1.4.x) as well as a brand new install that we just finished (2.4.1). Essentially, it seems like system.uptime overflows on Windows hosts and causes issues in ALL items / triggers / graphs on that host, not just uptime.
The setup:
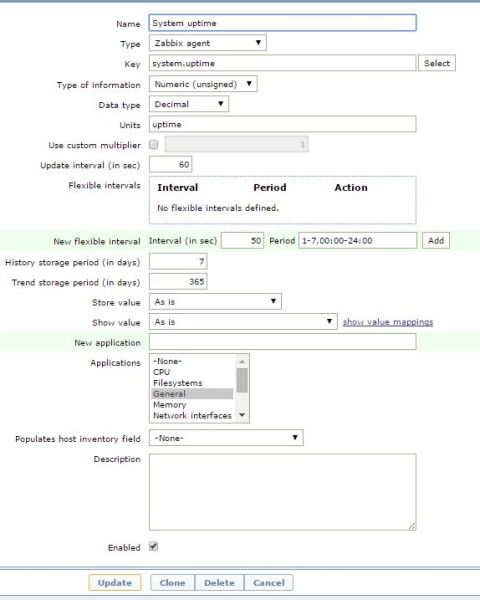
The stock/default 'System uptime' item that comes in the 'Template OS Windows' template with Zabbix (Item.jpg).
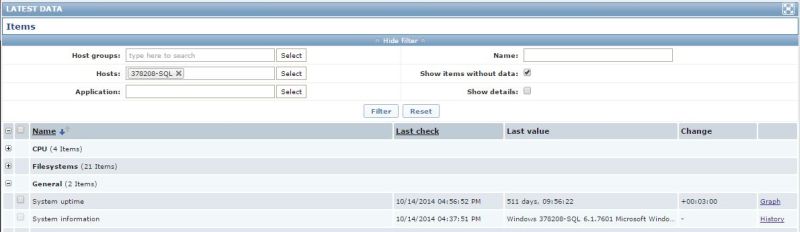
A Windows host with a long uptime, in our case it is currently 511 days (LatestData.jpg).
This causes drop outs in data, graphs, and triggers going off incorrectly, usually the "this host is unreachable / unable to contact Zabbix agent for 5 minutes". A good example is gaps in graphs (Graph.jpg)
Logs:
Host shows nothing out of the ordinary
Server shows a few lines like this:
12636:20141014:155738.603 [Z3005] query failed: [2006] MySQL server has gone away [begin;]
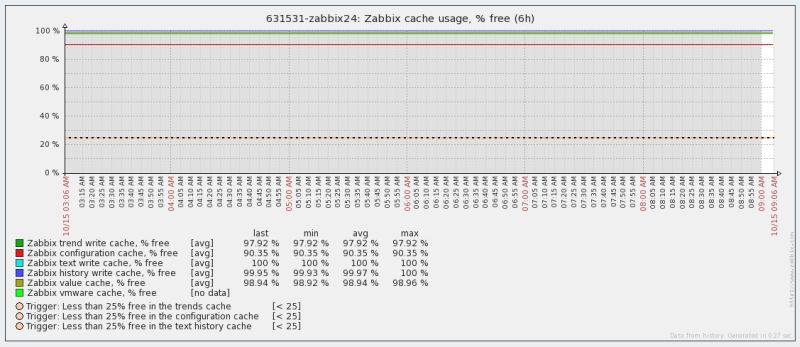
Zabbix health graphs don't seem to show anything (1.jpg-3.jpg)
My theory:
I assume that this is some sort of overflow issue, as ALL hosts will exhibit the same exact behavior right around the same uptime - a little bit before 500 days (seems to be about 497). It seems that Zabbix uses seconds for uptime, so with a quick calculation: 497 days * 24 hours * 60 minutes * 60 seconds = 42,940,800.
That number is very close to the upper bounds of a 32 bit number (2^32 = 4,294,967,296), just off by 2 decimal places. The only thing I can think of is that somewhere, Zabbix is using a 32 bit number (or some other data type) that overflows right at this value.
The worst part about this is: even if you totally disable / remove the system.uptime item, the issue still happpens. No matter what I try, every single one of our hosts is going to cause Zabbix to freak out right at ~497 days of uptime.
So, any ideas? Anything I can do to avoid this behavior (other than rebooting the host, of course)? I tried playing around with the "Store value" option, but that just always stores "1m" or whatever the interval is set to.
I seems like this issue should have come up for often, but I am unable to find any info on it. Thanks!