-
Type:
New Feature Request
-
Resolution: Fixed
-
Priority:
 Major
Major
-
Affects Version/s: None
-
Component/s: Agent (G)
Add a new item to support per process cpu utilisation monitoring: - proc.cpu.util[<name>,<user>,<type>,<cmdline>,<mode>]
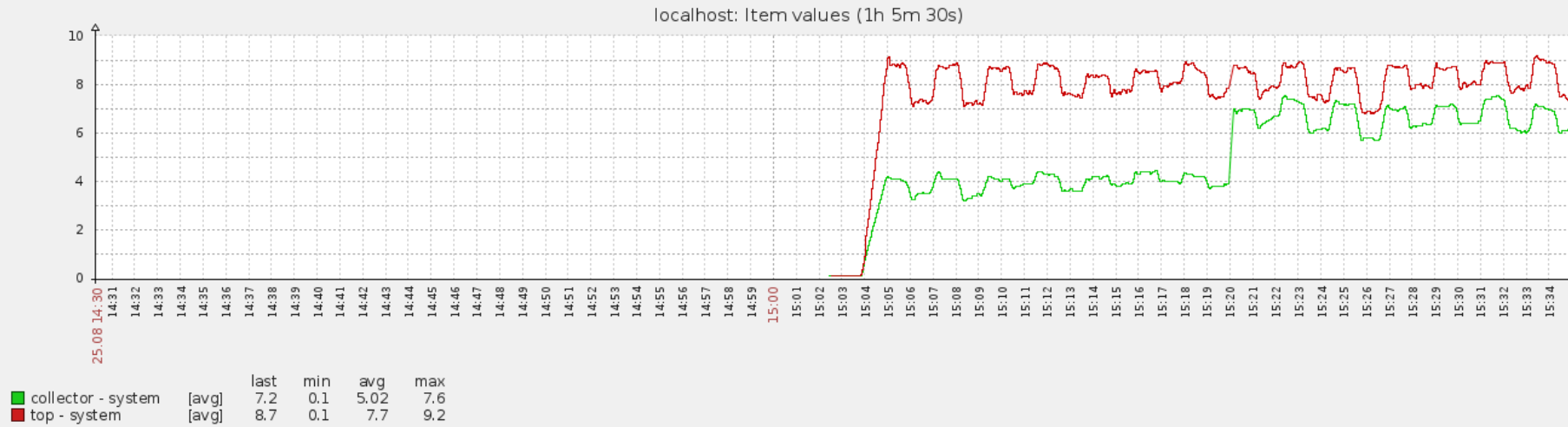
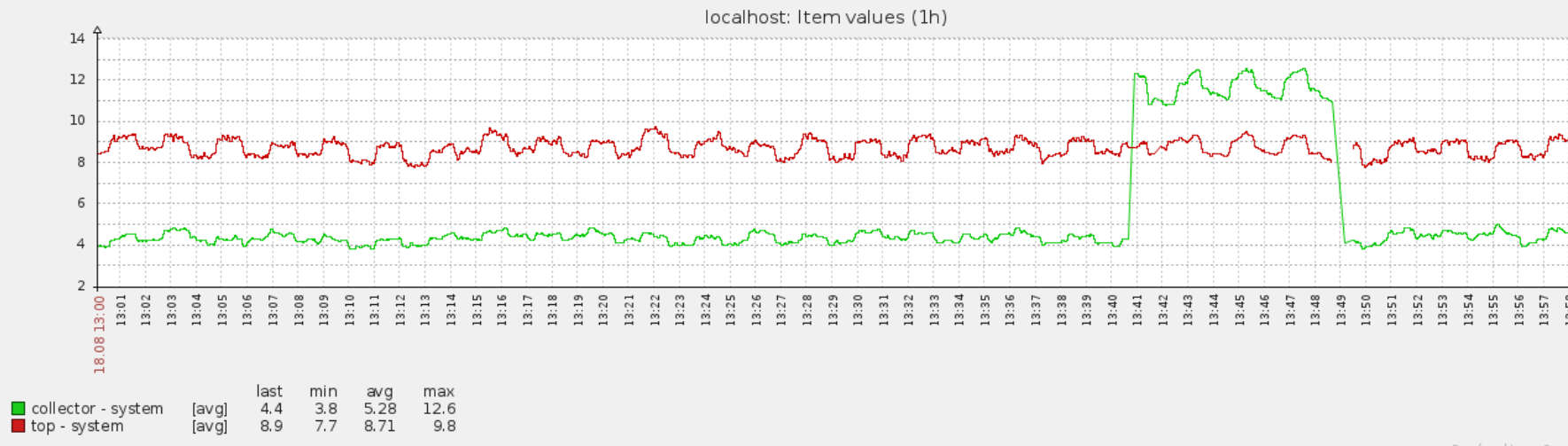
- is duplicated by
-
-
- Closed
-
-
-

- Closed
-
-
-

- Closed
-