-
Type:
Change Request
-
Resolution: Fixed
-
Priority:
 Major
Major
-
Affects Version/s: 5.0.42, 6.0.32, 6.4.17, 7.0.2
-
Component/s: Documentation (D), Frontend (F), Server (S)
-
None
-
Prev.Sprint, S24-W34/35
-
0.25
https://github.com/timescale/timescaledb/releases/tag/2.16.0
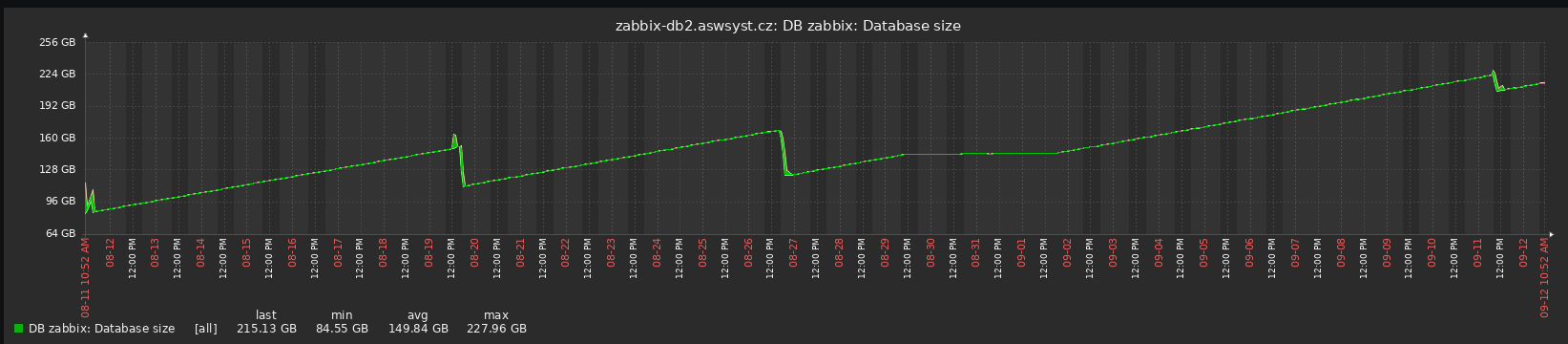
This release contains significant performance improvements when working with compressed data, extended join
support in continuous aggregates, and the ability to define foreign keys from regular tables towards hypertables.
We recommend that you upgrade at the next available opportunity.
In TimescaleDB v2.16.0 we:
- Introduce multiple performance focused optimizations for data manipulation operations (DML) over compressed chunks.
Improved upsert performance by more than 100x in some cases and more than 1000x in some update/delete scenarios. - Add the ability to define chunk skipping indexes on non-partitioning columns of compressed hypertables
TimescaleDB v2.16.0 extends chunk exclusion to use those skipping (sparse) indexes when queries filter on the relevant columns,
and prune chunks that do not include any relevant data for calculating the query response. - Offer new options for use cases that require foreign keys defined.
You can now add foreign keys from regular tables towards hypertables. We have also removed
some really annoying locks in the reverse direction that blocked access to referenced tables
while compression was running. - Extend Continuous Aggregates to support more types of analytical queries.
More types of joins are supported, additional equality operators on join clauses, and
support for joins between multiple regular tables.
Highlighted features in this release
- Improved query performance through chunk exclusion on compressed hypertables.
You can now define chunk skipping indexes on compressed chunks for any column with one of the following
integer data types: smallint, int, bigint, serial, bigserial, date, timestamp, timestamptz.
After you call enable_chunk_skipping on a column, TimescaleDB tracks the min and max values for
that column. TimescaleDB uses that information to exclude chunks for queries that filter on that
column, and would not find any data in those chunks.
- Improved upsert performance on compressed hypertables.
By using index scans to verify constraints during inserts on compressed chunks, TimescaleDB speeds
up some ON CONFLICT clauses by more than 100x.
- Improved performance of updates, deletes, and inserts on compressed hypertables.
By filtering data while accessing the compressed data and before decompressing, TimescaleDB has
improved performance for updates and deletes on all types of compressed chunks, as well as inserts
into compressed chunks with unique constraints.
By signaling constraint violations without decompressing, or decompressing only when matching
records are found in the case of updates, deletes and upserts, TimescaleDB v2.16.0 speeds
up those operations more than 1000x in some update/delete scenarios, and 10x for upserts.
- You can add foreign keys from regular tables to hypertables, with support for all types of cascading options.
This is useful for hypertables that partition using sequential IDs, and need to reference those IDs from other tables.
- Lower locking requirements during compression for hypertables with foreign keys
Advanced foreign key handling removes the need for locking referenced tables when new chunks are compressed.
DML is no longer blocked on referenced tables while compression runs on a hypertable.
- Improved support for queries on Continuous Aggregates
INNER/LEFT and LATERAL joins are now supported. Plus, you can now join with multiple regular tables,
and you can have more than one equality operator on join clauses.
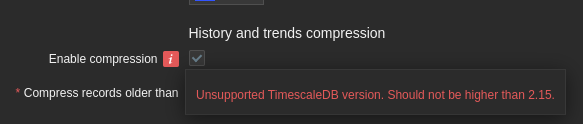
PostgreSQL 13 support removal announcement
Following the deprecation announcement for PostgreSQL 13 in TimescaleDB v2.13,
PostgreSQL 13 is no longer supported in TimescaleDB v2.16.
The Currently supported PostgreSQL major versions are 14, 15 and 16.
Features
- #6880: Add support for the array operators used for compressed DML batch filtering.
- #6895: Improve the compressed DML expression pushdown.
- #6897: Add support for replica identity on compressed hypertables.
- #6918: Remove support for PG13.
- #6920: Rework compression activity wal markers.
- #6989: Add support for foreign keys when converting plain tables to hypertables.
- #7020: Add support for the chunk column statistics tracking.
- #7048: Add an index scan for INSERT DML decompression.
- #7075: Reduce decompression on the compressed INSERT.
- #7101: Reduce decompressions for the compressed UPDATE/DELETE.
- #7108 Reduce decompressions for INSERTs with UNIQUE constraints
- #7116 Use DELETE instead of TRUNCATE after compression
- #7134 Refactor foreign key handling for compressed hypertables
- #7161 Fix mergejoin input data is out of order
Bugfixes
- #6987 Fix REASSIGN OWNED BY for background jobs
- #7018: Fix search_path quoting in the compression defaults function.
- #7046: Prevent locking for compressed tuples.
- #7055: Fix the scankey for segment by columns, where the type constant is different to variable.
- #7064: Fix the bug in the default order by calculation in compression.
- #7069: Fix the index column name usage.
- #7074: Fix the bug in the default segment by calculation in compression.
Thanks
- @jledentu For reporting a problem with mergejoin input order
https://github.com/timescale/timescaledb/releases/tag/2.16.1
This release contains bug fixes since the 2.16.0 release. We recommend that you upgrade at the next available opportunity.
Bugfixes
- #7182 Fix untier_chunk for hypertables with foreign keys
- duplicates
-
-

- Closed
-
- related to
-
-

- Closed
-


{kind=link}
{kind=link}
{kind=link}