|
Hello João,
Thank you for reporting the issue! Checked it and confirmed.
Regards,
Edgar
|
|
Hi,
Can you give us an estimate of when you expect to have this issue fixed?
Thank you!
Regards,
João Carvalho
|
|
I've managed to reproduce described scenario.
Here are the steps:
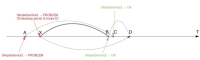
- Simple service 1 goes to PROBLEM state at A: 00:09:54.
- Simple service 2 goes to PROBLEM state at X, which points not to the current time, but to the future point D: 00:50:35. The problem is raised immediately though.
- Since both simple services are now in PROBLEM state, Complex service goes to a PROBLEM state too.
- Simple service 2 receiving OK event at B: 00:48:49.
- Complex service returns back to OK, because one of it's dependents became active.
- Simple service 1 receiving OK event at C: 00:48:54.
So, per my observations, Zabbix correctly manages service states.
However, negative problem duration makes confusion.
The time shift between X (actual problem state received by server) and D (timestamp of metric value) is likely caused by different time zones on agent and server.
So far it looks like we have to fix problem start time at current time (X) if it points to the future (D).
joao.g.carvalho Is that correctly describe your situation?
|
|
I believe that's the case.
I didn't realize that the PROBLEM was raised immediately.
In that case, you might have to do a retroactive correction, like I used to do before the events where marked as negative (v3.x.x).
But still, how come the simple service is correctly ignoring the negative problems? When does this happen? Is it immediate?
There should be a way to do the same for the complex service. It should feed itself on the dependencies positive events.
I noticed that the simple services add time to the total time of day (ex.: 1d 0h 1m). Is this part of the solution?
Thank you for the quick response!
|
|
Hi there,
Sorry for spamming the thread, but I'm a bit cofused!
I've only realized it now, that the Status has changed to 'resolved', and the Resolution is still 'unresolved'.
The Status tooltip says:
"A resolution has been taken, and it is awaiting verification by reporter. From here issues are either reopened, or are closed."
Are you waiting for my response? A confirmation that the problem was correctly reprodused, or fixed?
Do I need to do anything?
Anyway, It's my perception that the issue isn't fixed.
If I understood it correctly, you're saying that the issue isn't in the complex service. It's in the simple one, or elsewhere.
Be it so. The issue still exists.
If you're intention is to open a new thread do fix the root problem, and close this one, I have nothing to say.
But the issue doesn't seem fixed.
I didn't see a solution being presented.
As for the root problem,
I still find it suspicious that the simple services handle the negative problems correctly, but the complex ones don't.
For this reason, I don't agree with the answer:
- "So far it looks like we have to fix problem start time at current time (X) if it points to the future (D)."
First of all, this usually happens with outdated Zabbix Agents in Windows hosts (older that 4.2.x).
Some of these older agents send future timestamps, regardless of the real system time.
Restarting the agent solves this for a time. After a while, it starts happening again.
This as been fixed in the newer agents, and in the trigger events' evaluation.
One solution is to update all agents, and we've been doing so. But we still have some old ones.
Making sure that the host system time is correctly sincronized is also a good policy.
Unfortunately, this isn't the only situation in which negative events are created.
I've seen this hapen with ICMP simple checks. Don't know why. Latency, I suppose...
And we do have some services dependent on ICMP triggers.
It seems to me that the root of the problem lies in the complex services calculation.
If you say that it doesn't need fixing, and you believe you'll find the root of the problem elsewhere, than I think you need to identify the cause before closing this thread.
But that's just my opinion.
If this reads to you like a rant, I'm sorry! It's not my intention. I'm just trying to help.
Thank you for your time!
Regards,
João Carvalho
|
|
Hi joao.g.carvalho.
At the moment we are discussing a fix, which will correct (future) time for metrics received from the agents. That's why ticket status changed.
Anyway, we will take a look at complex service state calculation and ICMP simple checks as well.
By the way, similar time synchronization issues were discussed on forum:
Active agent items delayed - false alerts (Host unreachable)
Zabbix agent ping timestamp
Thank you for helping with issue investigation.
We appreciate that.
|
|
joao.g.carvalho
May it happen that ICMP simple checks have wrong (future) timestamps because of Proxy, which has time mismatch with the Server?
|
|
@Andrejs Tumilovics
It is very much possible. I'd have to check on that.
I might do so, if I find the time. Probably not today.
|
Feature proposal
Problem:
Active agent items are reported to the server with incorrect timestamp, which in some cases may point to the future.
Feature proposal:
When agent request a list of active checks, in response it receives current Zabbix server time.
Based on that time, Zabbix agent may calculate a delta between it's local time and server time.
Then, calculated delta may be applied to all outgoing active metric timestamps.
In such a way we may properly treat values from agents with out-of-sync. time.
Same approach may be applied to out-of-sync proxies.
Drawbacks: Network latency will not be corrected. Either way it's not corrected for passive checks.
|
|
Time correction between Server, Proxy and agent has been removed in Zabbix version 4.0 (documentation).
The one of reasons for that decision is delta calculation complexity.
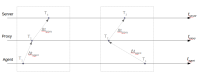
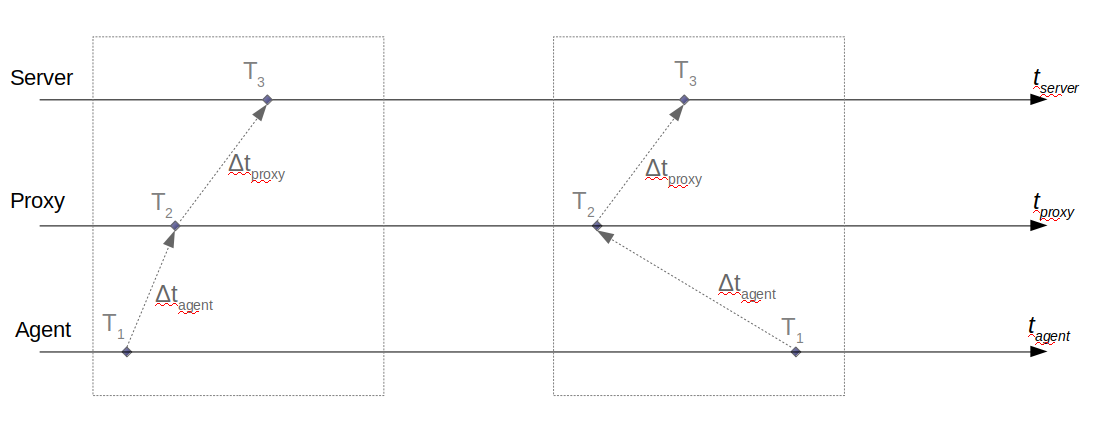
It's nearly impossible to properly calculate delta between T~1~ and T~3~ considering all latencies in between.
So, starting from Zabbix version 4.0, time synchronization between monitored nodes is not performed.
However, we understand that there may be many scenarios when time synchronization is complex:
- on limited resource controllers;
- on systems without internet connection;
- etc.
Currently we are discussing a new feature, which should help with time synchronization.
See above feature proposal.
For now, we may only suggest how to identify nodes with out of sync. time.
For that purpose you can use fuzzytime trigger function.
Otherwise there is not much we can do in scope of this ticket, so, I'm planning to close it and address this problem in terms of ZBXNEXT.
|
|
I think we fully discussed time adjustment in --ZBX-12957
I mean, the negative problem duration exactly indicates the problem, that the time on a monitored host is out-of-sync. By doing adjustments we hide this particular issue. Who knows what other problems might appear because the user forgot to turn on ntpd. Zabbix is the monitoring utility and yes, we should support monitoring of out-of-sync times, but not try to fix something that is not related to monitoring. We could as well start handling situations like some service reporting data in e. g. incorrect value type.
If we still decide to do the adjustments, I propose to have a separate option for that, disabled by default.
To me, this is Won't Fix and voting should be done on ZBXNEXT-3298 .
|
|
Hi there,
First of all, thank you for you analisys.
Anyway, I think we're getting 'off track' in this thread.
The issue isn't the trigger's behavior. For all I know, the issue regarding agent's data with wrong timestamps has been correctly addressed and resolved.
If either monitored server's or proxy's time is out of scync, this shouldn't be hidden. It reveals that de NTP is out of sync.
By the way, in the case that originated this thread, the negative problem was triggered by an outdated agent in a Windows server. The NTP wasn't out of sync. It is a know fact that zabbix agents prior to the 4.2.x version, in Windows servers, would often send data with an incorrect timestamp (usually over 5 minutes ahead of the system time).
Let me redirect the focus of the discussion to issue for which this thread was created.
The simple service correctly identifies a negative problem and therefore ignores it.
On complex services, if the algorithm is "if all children have PROBLEM", the negative problem will cause a incorrect evaluation.
What exactely does the simple service do when a negative problem is encoutered?
Why can't this be replicated to the complex services?
May I suggest a solution?
Before creating a problem event on the complex service, check if the event has a negative duration.
If possible, the event should've never been created in the first place.
Another solution is to do a retro-active correction.
Check these conditions every time a trigger reports a resolution:
- Is the trigger is related to a simple service?
- Is problem duration is negative?
- If so, correct the simple service (allready happens)
- Check if the simple service has a parent with the algorithm "if all children have PROBLEM".
- If it has, delete the complex service problem event, identified by the agent's incorrect timestamp.
Regards,
João Carvalho
|
|
joao.g.carvalho Just to clarify, when you say "correct calculation", you mean SLA calculation, right?
Or you are confused by service status indication in Monitoring -> Services?
I'm just wondering, because problems with negative duration were fixed for SLA calculation in -ZBX-14592
And fix should be there in version 4.2.4 you've specified in ticket description.
But, if we're talking about service status indicator, then, negative time problem is also shown with trigger severity in Monitoring -> Problems, until it's resolved (for simple service). However, according to your description I understood that "false problems" do not change simple service status.
Could you please check again your Zabbix server version, I'll probably have to use that particular one.
|
|
atumilovics, yes I meant SLA calculation.
I didn't realize the problem was fixed.
Sorry if I prolonged this discussion for longer than necessary.
Anyway, in --ZBX-14592
I guess we'll have to test it to find out.
Could we get a more detailed description on what was done in --ZBX-14592
|
|
joao.g.carvalho
ZBX-14592
- calculation of SLA by ignoring time period in which problem has negative duration;
- service availability report calculation by ignoring problems with negative duration.
Also, documentation was updated according to that change.
|
|
It must be checked how to accomplish this. Is changing the schema required? One idea is to remove original record that was added to service_alarms table when the problem was generated. A record to zabbix server log file must be a good clear one so people could be able to monitor such cases, just an idea:
|
|
Hi there,
I noticed the Status chaged to Manual Test Failed
I thought that ZBX-14592
Are you testing a diferent solution?
Regards,
João Carvalho
|
|
joao.g.carvalho
ZBX-14592 fixed the SLA calculation problem on front-end side.
Here we are making changes that alarms with negative duration are removed from DB. This is mostly for DB consistency, in case someone will pull data using REST API calls or directly from DB.
|
|
Hi,
It appears that the issue was fixed.
On the issue header, it says that the fix had been applied to 4.4.2rc1.
This release isn't available, so I assume that it's a test build, and that the fix will be implemented on the next 4.4 release.
We're currently on version 4.2, and we were planning on updating to 4.4.
We where hoping to have this fixed when we update Zabbix.
Can you give us an estimate on when the next release will be available?
Thank you!
Regards,
João Carvalho
|
|
Also,
Are you planning a 4.2 release?
Sorry for the spam!
João Carvalho
|
|
joao.g.carvalho, 4.2 is not supported anymore.
You can find release policy here: https://www.zabbix.com/life_cycle_and_release_policy
|
|
Thanks for the feedback!
Didn't know about the Life Cycle & Release Policy.
So, next relaese is due in March? LTS-5.0?
|
|
joao.g.carvalho you can find our roudmap here: https://www.zabbix.com/roadmap#v5_0
|
|
Problem description and proposed solution available here: ZBX-16543.pdf
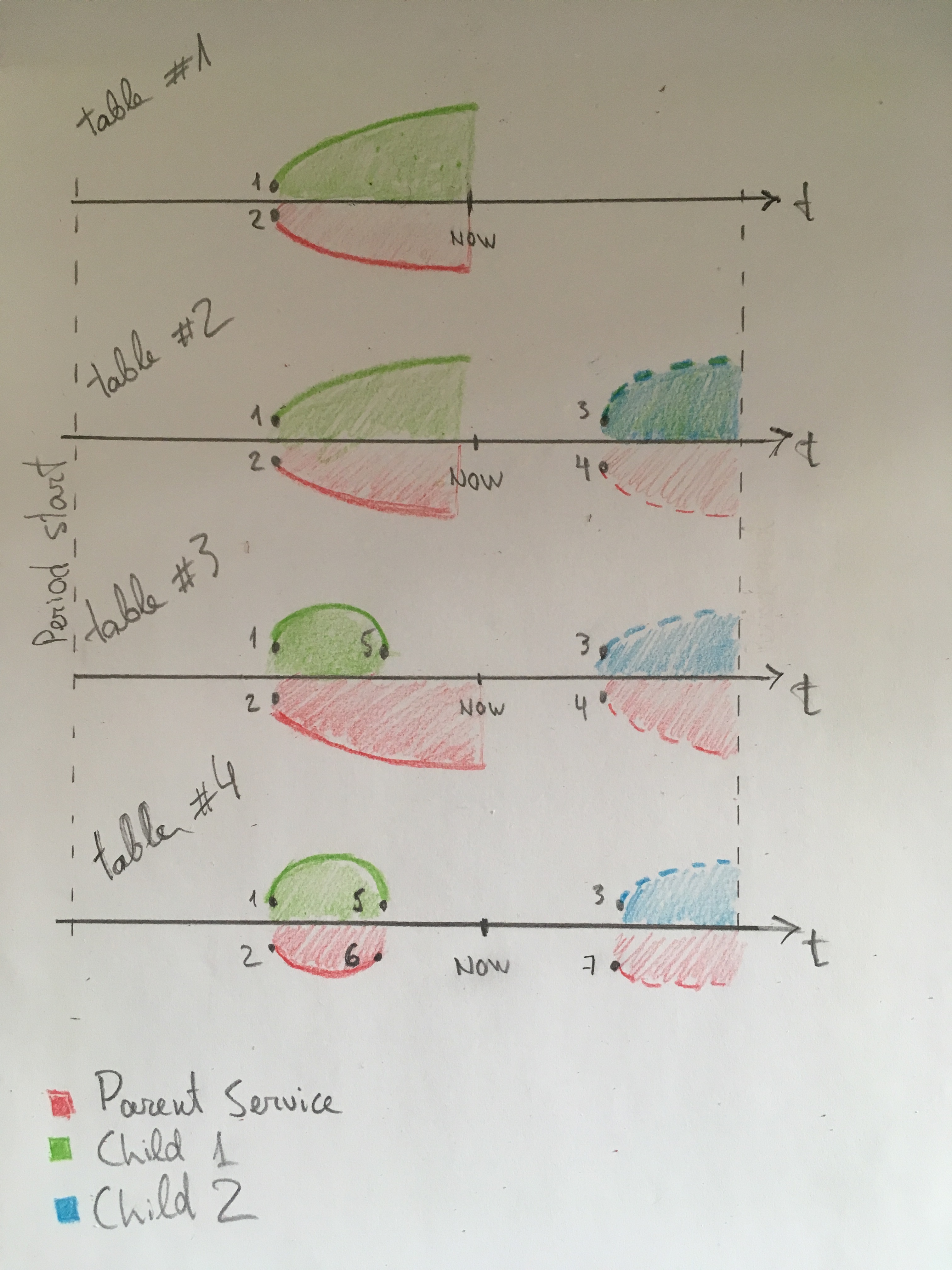
Here is an image visually displaying 4 tables described in attached PDF:
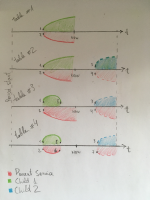
Some comments about image:
- Numbers are same as values in service_alarms.servicealarmid values;
- Regions with dashed line represents future events (currently negative) which are ignored for SLA;
- Table #3 shows error because problem time for parent service (red area) is not stopped at moment when child1 was stopped (green area). This happens because server doesn't check that remaining child1 service has negative duration;
- Table #4 shows proposed fix. Red problem time is now stopped and scheduled to start counting at moment when negative problem time becomes positive.
wiper: From the examples my guess would be that the problem is because of data not coming in chronological order. When server recalculates parent service status it uses current children status. If the event timestamp is in past it can lead to wrong parent status.
In that case possible solution would be to load service state historical data from service_alarms when loading service tree. Then the correct parent service state at specified timestamp could be calculated.
palivoda Why the data arrives not in chronological order?
wiper: There could be completely valid case when a parent service has children based on triggers from different proxies and one proxy was offline for some time. So yes, not good.
|
|
Could you please be so kind and let us know if you are still experiencing the problem joao.g.carvalho, thank you!
|
|
Hi, sorry for the late reply.
The conditions for the abnormal behavior are very specific, and they seldomly occur.
Even thoug this is rare, we have 12 services on which it can happen.
As a measure to minimise the probability of another event, we've made an effort to update every Zabbix agent to 4.2.1, or above.
Outdated agents on Windows machines can collect data with an incorrect timestamp, causing PROBLEMS with negative duration.
In turn, these PROBLEMS with negative duration can trigger an incorrect service evaluation.
Even so, network latency alone can cause a PROBLEM with negative duration. It sometimes happens, and we see it all the time.
Besides, some older SO's aren't compatible with the newer agent versions. We won't be able to update every single agent.
To answer your question,
That we've noticed, we haven't had any such incident again.
I guess that the required conditions haven't been met again. But it can still happen at any time.
We're not "experiencing the problem", but we still have the issue.
|
|
Hi,
Just to remind everyone of this support ticket.
We've upgraded to Zabbix 6.0, a few months ago.
Today we found out that this issue is still active
Regards,
João Carvalho
|
Generated at Sun Mar 29 14:36:46 EEST 2026 using Jira 10.3.13#10030013-sha1:56dd970ae30ebfeda3a697d25be1f6388b68a422.