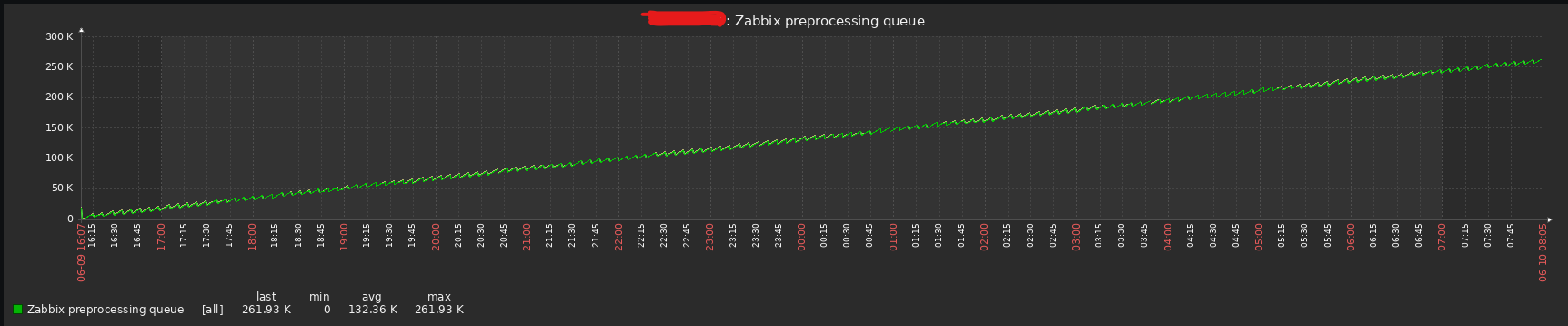
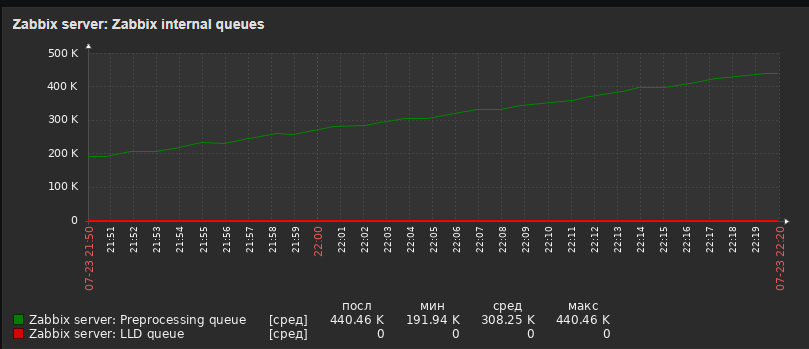
|
2 hosts, first with only default "RabbitMQ cluster by HTTP" Zabbix Template, and second with only default "RabbitMQ node by HTTP"
(This templates normally works with 5.4)
Cluster host has 8651 items (don't know how many dependent items, may be around 8000+)
Rabbit node host has 7765 items (17 regular items and another is discovered)
Some preprocessing from template
Some data
{"management_version":"3.9.8","rates_mode":"basic","sample_retention_policies":{"global":[600,3600,28800,86400],"basic":[600,3600],"detailed":[600]},"exchange_types":[{"name":"direct","description":"AMQP direct exchange, as per the AMQP specification","enabled":true},{"name":"fanout","description":"AMQP fanout exchange, as per the AMQP specification","enabled":true},{"name":"headers","description":"AMQP headers exchange, as per the AMQP specification","enabled":true},{"name":"topic","description":"AMQP topic exchange, as per the AMQP specification","enabled":true}],"product_version":"3.9.8","product_name":"RabbitMQ","rabbitmq_version":"3.9.8","cluster_name":"[email protected]","erlang_version":"24.0.6","erlang_full_version":"Erlang/OTP 24 [erts-12.0.4] [source] [64-bit] [smp:4:4] [ds:4:4:10] [async-threads:1]","disable_stats":false,"enable_queue_totals":false,"message_stats":{"ack":6068389,"ack_details":{"rate":12.8},"confirm":1072211,"confirm_details":{"rate":4.6},"deliver":6075147,"deliver_details":{"rate":12.8},"deliver_get":6075204,"deliver_get_details":{"rate":12.8},"deliver_no_ack":0,"deliver_no_ack_details":{"rate":0.0},"disk_reads":20773,"disk_reads_details":{"rate":0.0},"disk_writes":4887165,"disk_writes_details":{"rate":2.8},"drop_unroutable":4372,"drop_unroutable_details":{"rate":0.0},"get":55,"get_details":{"rate":0.0},"get_empty":0,"get_empty_details":{"rate":0.0},"get_no_ack":2,"get_no_ack_details":{"rate":0.0},"publish":6054309,"publish_details":{"rate":28.6},"redeliver":7770,"redeliver_details":{"rate":0.0},"return_unroutable":0,"return_unroutable_details":{"rate":0.0}},"churn_rates":{"channel_closed":856663,"channel_closed_details":{"rate":0.0},"channel_created":856820,"channel_created_details":{"rate":0.0},"connection_closed":237893,"connection_closed_details":{"rate":0.0},"connection_created":184371,"connection_created_details":{"rate":0.0},"queue_created":8,"queue_created_details":{"rate":0.0},"queue_declared":1550,"queue_declared_details":{"rate":0.0},"queue_deleted":4,"queue_deleted_details":{"rate":0.0}},"queue_totals":{"messages":59945,"messages_details":{"rate":-0.4},"messages_ready":59942,"messages_ready_details":{"rate":-0.4},"messages_unacknowledged":3,"messages_unacknowledged_details":{"rate":0.0}},"object_totals":{"channels":157,"connections":1623,"consumers":111,"exchanges":539,"queues":435},"statistics_db_event_queue":0,"node":"rabbit@rabbitmq-inf-p-01","listeners":[{"node":"rabbit@rabbitmq-inf-p-01","protocol":"amqp","ip_address":"::","port":5672,"socket_opts":{"backlog":128,"nodelay":true,"linger":[true,0],"exit_on_close":false}},{"node":"rabbit@rabbitmq-inf-p-02","protocol":"amqp","ip_address":"::","port":5672,"socket_opts":{"backlog":128,"nodelay":true,"linger":[true,0],"exit_on_close":false}},{"node":"rabbit@rabbitmq-inf-p-03","protocol":"amqp","ip_address":"::","port":5672,"socket_opts":{"backlog":128,"nodelay":true,"linger":[true,0],"exit_on_close":false}},{"node":"rabbit@rabbitmq-inf-p-01","protocol":"amqp/ssl","ip_address":"::","port":5671,"socket_opts":{"backlog":128,"nodelay":true,"linger":[true,0],"exit_on_close":false,"versions":["tlsv1.2","tlsv1.1","tlsv1"],"keyfile":"/etc/rabbitmq/key.pem","certfile":"/etc/rabbitmq/cert.pem","cacertfile":"/etc/rabbitmq/cacert.pem","fail_if_no_peer_cert":false,"verify":"verify_none"}},{"node":"rabbit@rabbitmq-inf-p-02","protocol":"amqp/ssl","ip_address":"::","port":5671,"socket_opts":{"backlog":128,"nodelay":true,"linger":[true,0],"exit_on_close":false,"versions":["tlsv1.2","tlsv1.1","tlsv1"],"keyfile":"/etc/rabbitmq/key.pem","certfile":"/etc/rabbitmq/cert.pem","cacertfile":"/etc/rabbitmq/cacert.pem","fail_if_no_peer_cert":false,"verify":"verify_none"}},{"node":"rabbit@rabbitmq-inf-p-03","protocol":"amqp/ssl","ip_address":"::","port":5671,"socket_opts":{"backlog":128,"nodelay":true,"linger":[true,0],"exit_on_close":false,"versions":["tlsv1.2","tlsv1.1","tlsv1"],"keyfile":"/etc/rabbitmq/key.pem","certfile":"/etc/rabbitmq/cert.pem","cacertfile":"/etc/rabbitmq/cacert.pem","fail_if_no_peer_cert":false,"verify":"verify_none"}},{"node":"rabbit@rabbitmq-inf-p-01","protocol":"clustering","ip_address":"::","port":25672,"socket_opts":[]},{"node":"rabbit@rabbitmq-inf-p-02","protocol":"clustering","ip_address":"::","port":25672,"socket_opts":[]},{"node":"rabbit@rabbitmq-inf-p-03","protocol":"clustering","ip_address":"::","port":25672,"socket_opts":[]},{"node":"rabbit@rabbitmq-inf-p-01","protocol":"http","ip_address":"::","port":15672,"socket_opts":{"cowboy_opts":{"sendfile":false},"port":15672}},{"node":"rabbit@rabbitmq-inf-p-02","protocol":"http","ip_address":"::","port":15672,"socket_opts":{"cowboy_opts":{"sendfile":false},"port":15672}},{"node":"rabbit@rabbitmq-inf-p-03","protocol":"http","ip_address":"::","port":15672,"socket_opts":{"cowboy_opts":{"sendfile":false},"port":15672}},{"node":"rabbit@rabbitmq-inf-p-01","protocol":"http/prometheus","ip_address":"::","port":15692,"socket_opts":{"cowboy_opts":{"sendfile":false},"port":15692,"protocol":"http/prometheus"}},{"node":"rabbit@rabbitmq-inf-p-02","protocol":"http/prometheus","ip_address":"::","port":15692,"socket_opts":{"cowboy_opts":{"sendfile":false},"port":15692,"protocol":"http/prometheus"}},{"node":"rabbit@rabbitmq-inf-p-03","protocol":"http/prometheus","ip_address":"::","port":15692,"socket_opts":{"cowboy_opts":{"sendfile":false},"port":15692,"protocol":"http/prometheus"}}],"contexts":[{"ssl_opts":[],"node":"rabbit@rabbitmq-inf-p-01","description":"RabbitMQ Management","path":"/","cowboy_opts":"[{sendfile,false}]","port":"15672"},{"ssl_opts":[],"node":"rabbit@rabbitmq-inf-p-02","description":"RabbitMQ Management","path":"/","cowboy_opts":"[{sendfile,false}]","port":"15672"},{"ssl_opts":[],"node":"rabbit@rabbitmq-inf-p-03","description":"RabbitMQ Management","path":"/","cowboy_opts":"[{sendfile,false}]","port":"15672"},{"ssl_opts":[],"node":"rabbit@rabbitmq-inf-p-01","description":"RabbitMQ Prometheus","path":"/","cowboy_opts":"[{sendfile,false}]","port":"15692","protocol":"'http/prometheus'"},{"ssl_opts":[],"node":"rabbit@rabbitmq-inf-p-02","description":"RabbitMQ Prometheus","path":"/","cowboy_opts":"[{sendfile,false}]","port":"15692","protocol":"'http/prometheus'"},{"ssl_opts":[],"node":"rabbit@rabbitmq-inf-p-03","description":"RabbitMQ Prometheus","path":"/","cowboy_opts":"[{sendfile,false}]","port":"15692","protocol":"'http/prometheus'"}]}
|