|
Duplicate |
|||
|
Sub-task |
|||
| depends on |
|
Nodata triggers after proxy becomes a... | Closed |

[ZBX-23633] Service alarms storing values in wrong order and affecting the SLA Created: 2023 Oct 31 Updated: 2024 Apr 10 Resolved: 2024 Mar 01 |
|
| Status: | Closed |
| Project: | ZABBIX BUGS AND ISSUES |
| Component/s: | Server (S) |
| Affects Version/s: | 6.4.6 |
| Fix Version/s: | 6.0.26rc1, 6.4.11rc1, 7.0.0alpha9, 7.0 (plan) |
| Type: | Problem report | Priority: | Critical |
| Reporter: | Victor Breda Credidio | Assignee: | Vladislavs Sokurenko |
| Resolution: | Fixed | Votes: | 12 |
| Labels: | None | ||
| Remaining Estimate: | Not Specified | ||
| Time Spent: | Not Specified | ||
| Original Estimate: | Not Specified | ||
| Environment: |
Zabbix server and proxies running on containers (podman). |
||
| Attachments: |
|
||||||||||||
| Issue Links: |
|
||||||||||||
| Team: | |
||||||||||||
| Sprint: | S2401-1, S24-W6/7, S24-W8/9 | ||||||||||||
| Story Points: | 0.5 | ||||||||||||
| Description |
|
Hi, As for the negative event occurrence, we have checked over and over, but it doesn't seem to be cause by unsynced time between Server and Proxy, for example. We have a NTP server that is taking care of our whole network and all the time we check, it is synced up. The type of items related to this are always ICMP ping items. Time between hosts synced: This behavior seems be going against what is defined on the Documentation:
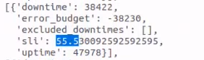
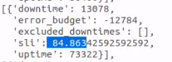
As it is indeed affecting the our SLAs report. As a workaround, as already mentioned, we are having to apply changes manually to obtain the correct SLI and SLA report.
** |
| Comments |
| Comment by Leandro Dethloff [ 2023 Nov 01 ] |
|
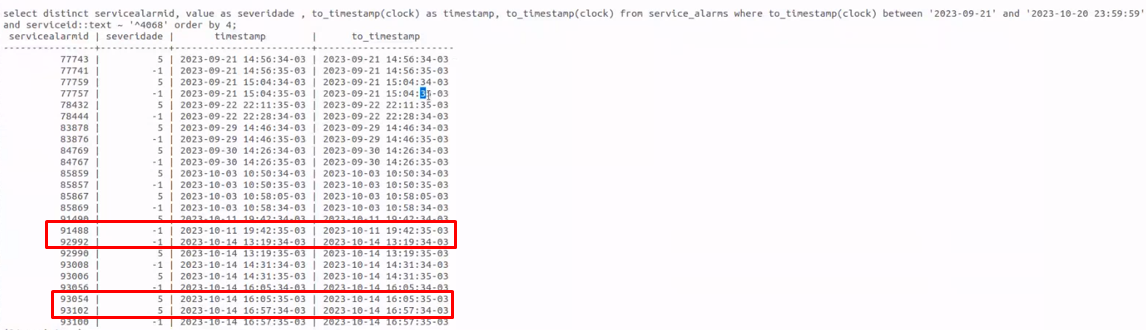
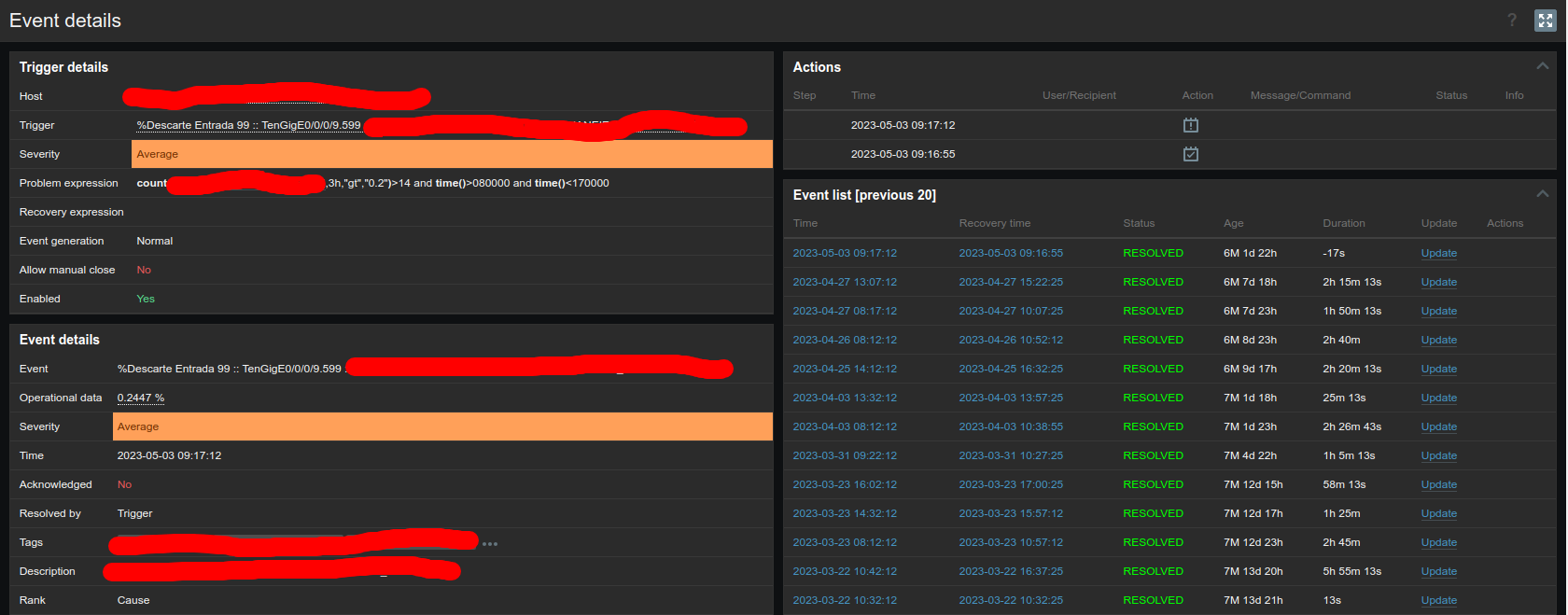
The error also occurs in other types of items, as we can see in the attached image. However, in this case, since it is not associated with a service ID, it does not present the same error in the alarms table, only in the events table.
|
| Comment by Leandro Dethloff [ 2023 Nov 14 ] |
|
6.4.7 we have the same problem |
| Comment by Vladislavs Sokurenko [ 2023 Dec 15 ] |
|
Fixed in:
|
| Comment by Marianna Zvaigzne [ 2024 Jan 05 ] |
|
Documentation updated: |
| Comment by Leandro Dethloff [ 2024 Feb 08 ] |
|
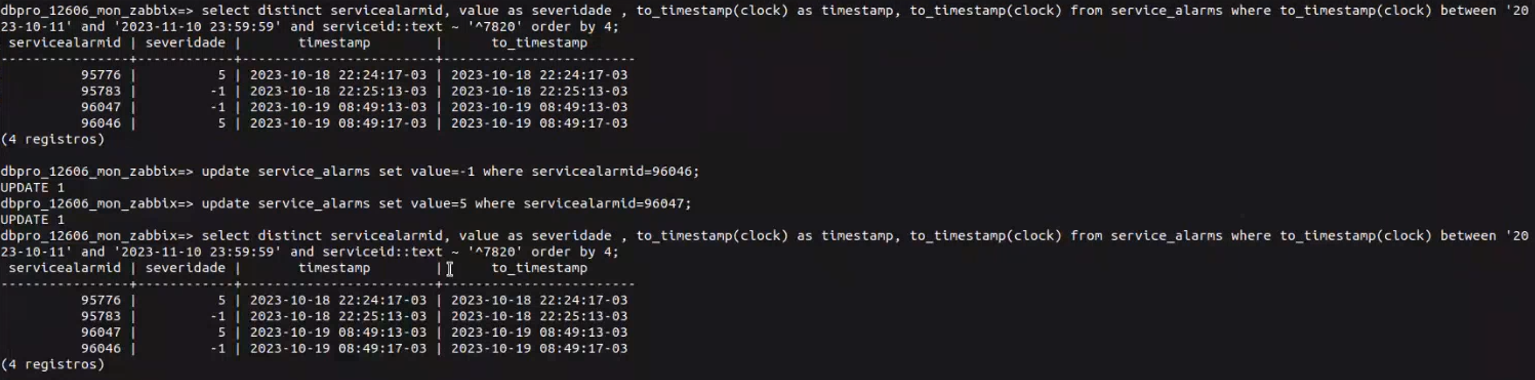
This bug continues to occur in the current version, only in a worse way, because now in the 'service_alarms' table it simply places the start and end of the event with the date of event recovery, and in the 'events' table it keeps the times inverted.
We can never have events with inverted recovery dates because the user will handle the event on the event screen, and when they discard the event, how will they know how long it lasted? |
| Comment by Vladislavs Sokurenko [ 2024 Feb 09 ] |
|
Problem with negative durations don't actually last as they have negative duration, what should be the expected behaviour ? |
| Comment by Leandro Dethloff [ 2024 Feb 09 ] |
|
The event did indeed occur. It's important to understand that it's recording the downtime and recovery time in reverse. These events cannot simply be ignored in the service_alarms table, as we have a tag in the trigger that is used as a problem_tag. It cannot be ignored to avoid affecting the service level, as this event did indeed impact the service level. |
| Comment by Vladislavs Sokurenko [ 2024 Feb 09 ] |
|
So it should use actual time when received recovery event if there was negative duration ? |
| Comment by Leandro Dethloff [ 2024 Feb 09 ] |
|
Negative duration is a bug in Zabbix when the server saves the collected data in the database. This should not continue to happen. This event should have been logged with the correct start and end times, and not with the times reversed. This would have sent the event to the service_alarms table, since it is a real event that affected the service level. This bug has been around since version 5.0 and it occurs so often that we've nicknamed it "Back to the Future", because the start and end times of the event are reversed. |
| Comment by Vladislavs Sokurenko [ 2024 Feb 09 ] |
|
For that reason there were changes in |
| Comment by Leandro Dethloff [ 2024 Feb 09 ] |
|
In our environment, all hosts are monitored by proxies. We are unable to reproduce the "back to the future" bug in the Zabbix because we cannot identify the cause of this issue. The start and end times are recorded in reverse order ( like the zabbix documentation https://www.zabbix.com/documentation/6.4/en/manual/web_interface/frontend_sections/monitoring/problems#negative-problem-duration ). |
| Comment by Leandro Dethloff [ 2024 Feb 09 ] |
|
In our environment, we do the following to correct this event timestamp deviation:
One suggestion would be to have a process or business rule in the code that writes the event to the database to check if the last record for that trigger is a drop or a recovery.
|
| Comment by Vladislavs Sokurenko [ 2024 Feb 13 ] |
|
Dos it mean that if problem is resolved with negative duration then it should use time when it is actually resolved ? Could you please be so kind and provide more information about the trigger, does it use nodata function or simply timestamps of historical data are incorrect for some reason ? |
| Comment by Leandro Dethloff [ 2024 Feb 15 ] |
|
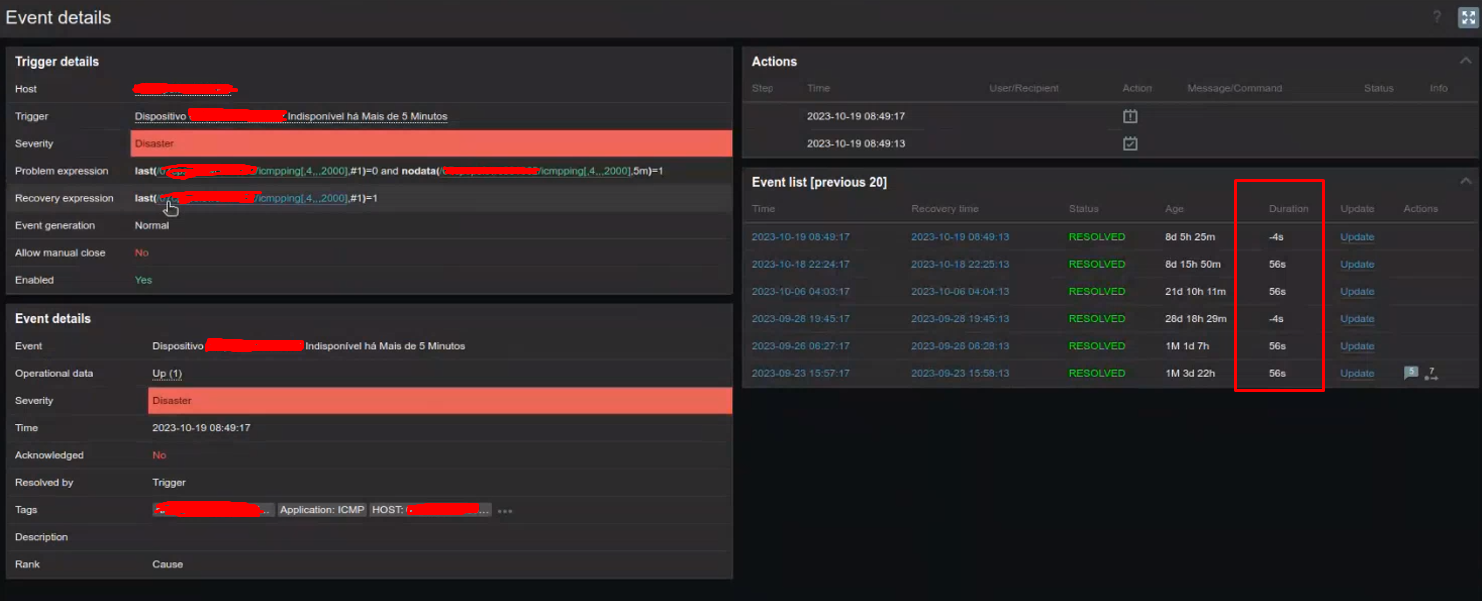
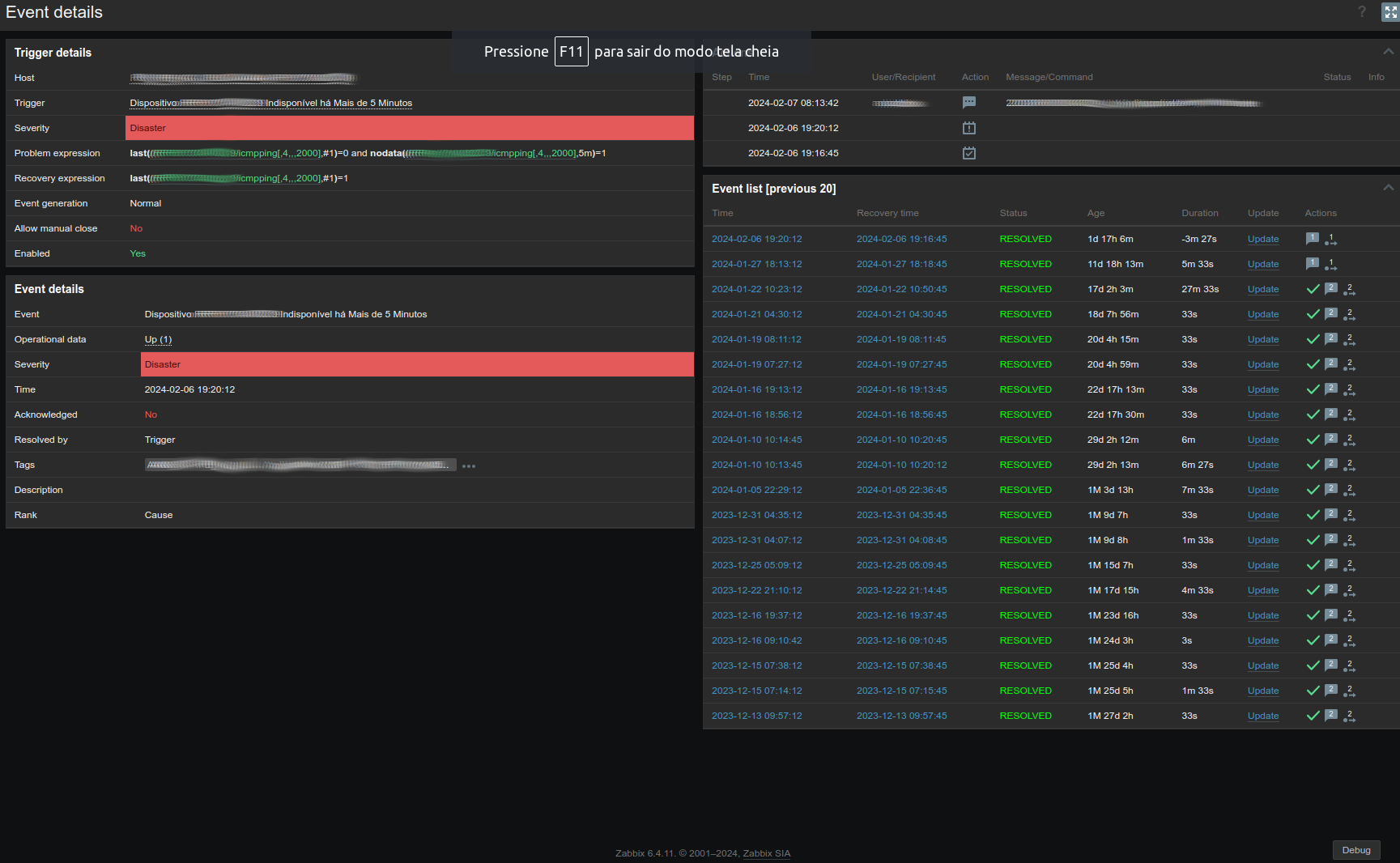
Yes my problem expression uses nodata function in trigger as i sent a print 6 days ago and as you can analize bellow.
|
| Comment by Vladislavs Sokurenko [ 2024 Feb 19 ] |
|
Could you please check, was it intentional trigger expression last()=0 and nodata()=1, shouldn't it have been last()=0 or nodata()=1 ? It should help to work around the issue. |
| Comment by Leandro Dethloff [ 2024 Feb 19 ] |
|
If I simply replace AND with OR, the expression loses its meaning. The ping trigger has a 6-hour heartbeat today (I had already changed it, it was 24 hours before). The trigger says: If the value is 0 (dropped at minute 1) (first part of the expression) AND there is no data for 5 minutes (second part of the expression) it ALARMS If I put OR, it will alarm both when the trigger is 0 (at minute 1) (first part of the expression) and if the link has no data for 5 minutes (all hosts would alarm every 5 minutes, since the heartbeat will only be saved every 6 hours). What is your suggestion to improve the trigger in this case without generating a large increase in the data that would be written to the database? |
| Comment by Vladislavs Sokurenko [ 2024 Mar 01 ] |
|
Main question is if issue is happening due to historical values having incorrect timestamp and why or something else is causing it. |
| Comment by Vladislavs Sokurenko [ 2024 Mar 01 ] |
|
Original problem with SLA has been fixed in this ticket, other mentioned issue with proxy should be fixed under |
| Comment by Leandro Dethloff [ 2024 Mar 01 ] |
|
No, this happens every day and the proxies are always available and stable, and all monitoring is done through proxies. And no, the unresolved SLA issue persists. Unless you consider simply ignoring an event when it is negative to be a solution for the deviation, which is what happens in version 6.4.11. We understand that negative events cannot occur and that an event manager is needed to prevent this type of information from being recorded in the database. The event occurs and the start and end dates are recorded in reverse. Do you believe that this would not happen in an environment without proxies? In my case, this is impossible, I really need to use proxies.
|
| Comment by Vladislavs Sokurenko [ 2024 Mar 01 ] |
|
It's possible that it is issue mentioned in |
| Comment by Leandro Dethloff [ 2024 Mar 01 ] |
|
I scanned all the events that occurred and that are linked to serviceids, they occur on all my proxies and yes, I have another Zabbix just to monitor this environment and I know when a proxy is down, and they don't have periods of instability or downtime that would cause the collection deliveries to the server to be delayed. The most curious thing is that the proxy with the most occurrences is the one that is on the same network as the server and despite being the one with the most load it has a VPS of only 191.35 with 8 CPUs and 16GB of memory and these resources are always left over. The second place in number of occurrences has an even smaller VPS 56.53 |