|
Push after 1 year for this important feature.
|
|
Yes! It would also be super-useful to be able to templatise host dependencies for a site/installtion, possibly by adding host-type/function descriptors, so that a topology of dependencies could be applied to groups of hosts. You could then definesomething like "webserver depends on edge switch depends on router" for multiple sites or like topologies.
|
|
Coming from using Nagios this is a feature that is sorely missed and would greatly simplify dependencies.
|
|
+1 for this important feature
|
|
+1 for this feature too! Will love to see it implemented.
|
|
+1!
|
|
please, use the jira voting system, don't pollute the comments 
|
|
Any progress? This is a very important feature!
|
|
ZBXNEXT-1461 is loosely connected
|
|
Of the top 12 requests, this is the oldest without any kind of workaround, and it's been open 5 years! wow!
|
|
Any progress?
|
|
+1 very important! At least, some GUI to mass updates trigger dependencies per host, not per trigger. But when managing larger deplayments, per-trigger dependencies are so complicated and overhelming.
|
|
Hey, as I can imagine, that programming host dependencies is quiet a big deal, I just had the following idea: Why not implement host-based dependencies as maintenance times?
if(trigger_flagged_for_host_is_down) {
foreach(dependencies as host)
{
put_host_in_maintenance(host, "reason");
}
}
This could work out-of-the-box
|
|
If this feauture would be implemented then it can truely scale.
|
|
This is the key feature that has kept me for a number of years from implementing Zabbix and really seems to be the only system I have run into not supporting this. Will keep checking back every 6-12 months for it to be added as I have been.
|
|
I dont know why do you refuse to develop this feature. I think its very simple and useful. Doesn't seem to be hard to include it. Its just the same feature that the one about triggers but host-related.
After 4 years since this feature was requested and no one gave it a try, i lost my hope on this.
|
|
This done along with ZBXNEXT-1891 would be great
|
|
For simplicity and efficiency reasons I'd prefer to improve the existing trigger based dependencies.
Not well thought-out but I think of host dependencies based on trigger(s). Similar to how it is already done for triggers itself.
On host/template level one may add a dependency from a trigger (or multiple triggers, of course). This trigger is then implicitly added to all the other host/template triggers as dependency.
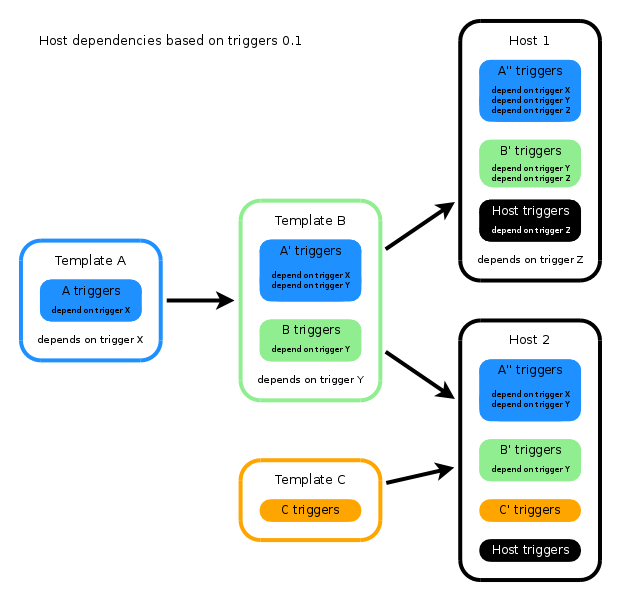
|
|
This is a huge hole in the Zabbix feature set. It's sad to see this request will be 5 years old tomorrow.
|
|
Unfortunately without this feature Zabbix is not practical for monitoring a medium to large network. Was hoping to get our networks team to move across to Zabbix but we will have to continue to maintain Nagios for them 
To keep it simple would it be better to build dependencies using the IT Services hierarchy and only notify for the parent service rather than all the children.
|
|
+1!
This is really needed in our enviroment too!
|
|
+1!
I need host dependency like a nagios.
|
|
We have been using zabbix for years despite this shortcoming. We are happy with the product, but this is a problem that needs to be addressed. We use alot of proxies and have customers with complex networks. At the moment when a router or internet connection is offline we get hundreds of alarms.
|
|
Well, there is still the option of (co-) sponsoring the development 
|
|
Excellent suggestion Marc, did not realize this was an option. I have contacted them to see what the cost might be for this. Once determined let's get it over here and hopefully we can all contribute to this missing critical feature. Once Zabbix has this, will be our choice going forward. Thanks!
|
|
Larry - reply to the thread if you decide to contact them to do the custom development. My company may want to help co-sponsor the development of this feature, as well.
|
|
I hope more people will vote for this feature request. It would make my life so much easier! Hopefully it will see the light in the next major release.
|
|
If I could vote against this feature, I would do so.
There is no "host dependency" because there is no difference between a "host" being down and a trigger on that host being in a PROBLEM state.
The only thing you have to do to implement "host dependencies" in the existing system is to establish how you decide a system is "down" (rather than in a degraded or mildly non-optimal state). If you decide that it's "down" because one of its interfaces doesn't respond to ICMP echo (ping), then create a template that has just the ping test in it and create a trigger on that ping test to be in a PROBLEM state when ping doesn't respond. (Remember that by default, the "simple check" ping test in Zabbix returns "OK" if ANY of THREE ping tests comes back okay.)
Then you have a template you can apply to any host that you want as a dependency for other hosts. All hosts with this template have a common trigger name, for ease of deployment.
Essentially, there is no "host dependency" because there is no "host test" to tell if a host is up. You can't get around having an item and a trigger to tell you if the host is up, which is host Zabbix is already built.
I am using Zabbix to monitor a network with a couple hundred nodes (does that count as "medium to large"?) without any trouble. I don't see the issue here.
|
|
I agree with you Justin. The Host based dependencies in Nagios for example require that you specify an individual "check" to determine if a host is up which pretty much mimics the design you noted above.
We have a Ping template in Zabbix with a single threshold looking for 100% packet loss. This is applied to all hosts and we have a script that maps out all of the trigger dependencies from our CMDB.
This works exceptionally well for us (except for ZBX-4344) and is significantly more flexible that the host based dependencies in Nagios which does not allow us to map dependencies on other item checks.
|
|
This issue/problem is Ryan's comment "This is applied to all hosts and we have a script that maps out all of the trigger dependencies from our CMDB." I am not saying this cannot be manually emulated, but when you have 1000's (10's of thousands) of checks and need to map that as a dependency for each one it is either a very painful manual process or you need to create scripts that somehow "know" how to map dependencies from one device to the other. Creating a host (parent / child is really what we need) dependency and then saying if parent is not up (or better parents if this device has multiple upstream paths) don't bother with other checks and cascade this down significantly simplifies the setup and stops the alert storms pretty easily.
|
|
I agree with both sides of the coin with this. Although, when doing this stuff at a large-scale there is definitely a need for both. I agree with Volker Fröhlich's views.
There needs to be more of a focus on multiple correlation aspects (either be by topology, host, trigger, etc). This definitely becomes a factor when having to perform this across a large number of devices. Especially when performing this for neighbouring devices in a large network.
These enhancements would help alleviate or make these tasks easier to maintain:
"Give an indication/allow to browse through dependent triggers"
https://support.zabbix.com/browse/ZBXNEXT-1949
"Provide an API option to obtain dependent triggers for trigger.get()"
https://support.zabbix.com/browse/ZBXNEXT-2554
"Notify dependent triggers with an indication of the root problem plus dynamic dependency maps"
https://support.zabbix.com/browse/ZBXNEXT-1461
Volker presented an interesting and insightful talk (Zabbix 2012 conference) on this approach for the above enhancement:
https://www.youtube.com/watch?v=Sv0ZV05N5oI
Large toolsets often go down the parent/child elements route in a large topology where there is correlation done between child being linked to parent. Where there is also the ability to define specific conditions/rulesets (if required - to allow for exceptions to the rule).
As a result of being linked to parent, child is treated as a symptom rather than the 'cause' as it is only a neighbour. The root of the problem has been identified to be further upstream in the chain.
In this case from the point that is closest to the Zabbix server. This would be a dynamically populated topology based on device discovery.
This approach would allow for more accurate dependency rules being able to be defined.
|
|
It would be nice if we schedule a maintenance of a host, zabbix couldn't inform alerts of the hosts that depends on the selected host.
|
|
Any news about this feature request?
It would help a lot on my work.
|
|
If it was possible to set with a checkbox a trigger that is the root trigger os a host things would be simpler.
All triggers that make use of a item from a host should be dependend from the root trigger.
If you put a host that depends on another host, that should create a dependency between the root triggers.
This feature is implemented on Nagios and is really nice.
I know that some of you don't agree but take a loot at the number of votes of this feature.
|
gmsousa
Any news about this feature request?
It seems not to be on the roadmap yet. Maybe see my comment for one way to get it there
|
|
Any progress on that BASIC feature?
|
|
Another Vote for host dependencies. Yes there are labor intensive work arounds, but this is a standard feature in nearly all monitoring tools and a glaring omission in this one.
|
|
This is the 4th top voted feature, has been here for 6 and a half years and hadn't any attention from zabbix developers? To be honest, the 6 top voted features aren't assigned to any developer...
We come from nagios (several years ago, already) and this is one of the basic (as kyob noted) features that we miss. The flexible trigger based dependencies is valid, but you don't have a simple way to say "if the router (or switch) is down then don't notify me about every host behind it" or "if the Xen server is down then don't notify me about every virtual host in there".
Like it's now, we may receive hundreds of messages per notified user in case a Xen server has a problem.
Yes, we may not have a good approach that fixes this issue (like Justin said in comment-131309), but it would just be a work around on the problem that the product (zabbix) has.
|
|
This is really a Shame,
I am at the point to review POC setup to our Cloud structure and this was the question from our Application and network team. the basic need or host / Application dependencies.
If this is not a major feature, - at least a work around will be great.
Thanks
|
|
for everybody who is interested in this, please discuss it on IRC and other channels, mentioned in http://zabbix.org/wiki/Getting_help - it is quite possible that somebody there will suggest how to use trigger dependencies to solve your usecase
|
|
Trigger dependencies solve this problem for us pretty good now. The only issue we're still having is that some hosts have multiple uplinks. When only one of the uplinks is down, it should still be a problem when the host is not reachable. In the current system, if any of the dependencies has a problem, the trigger is ignored.
I was wondering if a patch implementing something like ZBXNEXT-1547 would be accepted.
On the server side, the biggest change would be in DCconfig_check_trigger_dependencies_rec, to make it continue when the 'operator' is AND (this part, I already have).
On the frontend, the change is slightly bigger, because the current code that checks if a dependency has a problem does not work recursively, making it harder to implement this.
It would then look something like this:
https://ikke.info/i/zabbix_dependency_1.png
https://ikke.info/i/zabbix_dependency_2.png
Would a change like this be accepted if I would provide the patches?
Thanks.
|
|
Hi, Kevin!
Cannot promise accepting a patch without seeing the patch
It is worth to develop a patch - it can be a catalyst ("see how simple it can be solved") for further work. Experience shows that user-submitted patches are rarely applicable "as-is". Often a patch solves immediate need for a user on one platform and requires full-time developer work to integrate it into product road-map, on all platforms, to fit coding guidelines, to be robust in various edge-cases, to provide good error diagnostics, to play well with other features, to be compatible with other versions (if required) and so on.
If patch is closer to ZBXNEXT-1547 maybe discussion can be moved there.
|
|
Just wondering whether event tags resp. event correlation could help here too.
Regarding Zabbix proxy dependencies I could think of a scenario like the following one. Obviously this would require the Macro {PROXY.NAME} to be resolved in tag values and a new condition type Event tag value pair.
Event tags of a Trigger representing a Zabbix proxy availability
Proxy
Proxy name = Zabbix proxy Foobar
Event tag of every other Trigger
Proxy name = {PROXY.NAME<1-9>}
Global event correlation rule
Condition
Old event tag = Proxy
Old event tag value Proxy name = new event tag value Proxy name
Operation
Close new event
|
|
The last comment works, but there is the problem if you have any other problems behind the problem you always get one alert. Depending on what you want to do it is maybe not useful to do it that way. You have maybe not an eye on all problems in your infrastructure.
|
|
In two months, this request will be 8 years old. It is the third most voted feature request also. Is it that hard to implement? We are using Zabbix for a year with no problem for our servers, but once we started migrating our switches, routers and APs from Nagios, it became such a pain to maintain dependencies. We are not that huge, but we have like 300 of them, and chains of up to 15 devices... It would be so good to just flag the parent to make a host dependent on. There is another uses for this feature also. For example, some times we have problems with a port in a switch that makes another switch down. With Nagios, we clicked in the down host, then we already could see the parent, and connect to it, see if there is a problem with the parent, or its ports, and fix it faster.
This could be used to make basic maps automatically too.
|
|
markkrj, the point is, there is not the one and only valid design thinkable. This feature could be implemented in many respects with possibly slight but significant differences regarding the use case.
However, the best is probably (co-)sponsoring development to at least finance the assessment and an appropriate design proposal. Who knows, possibly this has already been done and the plan lays in a drawer waiting for the little left gap to be sponsored...
Consider to get in touch with sales at zabbix dot com and ask for the status/sponsoring of this feature. Doing so doesn't cost a thing
|
|
I inquired about co-sponsoring this feature on August 14th. So far no reply, I just sent a reminder and will keep you updated on further developments...
|
|
Got an answer from Zabbix sales team. They are looking for other sponsors now and are ready to ship this feature with Zabbix 4.0 once development costs are covered. Please feel free to contribute if you need this feature
|
|
We needed this feature 3 years ago unfortunately and have moved on (NetXMS) and have been pleased with what it can do for us. There are still a number of parts to Zabbix that are really nice though. Good luck with getting this implemented it is a huge hole in the product.
|
|
My only wish from the new year.
|
|
I had an idea on how to work-around this for now... After yet another weekend of our firewall going down, causing our site-to-site VPN tunnel to production to go down... Which fired off a consistent stream of 10,000 pages to my phone.
The idea is this:
- 1. Create a new host, with a single item. The internal IP of something behind your firewall. Or your firewall device, whatever. For me, it will be an IP on the firewall that is accessible only from the inside network of the VPN tunnel.
- 2. Create a template that would create a ping check to that internal IP in a trigger that would be set up to run an "Action".
- 3. The Action would, instead of send a page to you or whatever you usually do, run a command on the zabbix server that would call out to the zabbix API to put all production groups into maintenance mode. We already have an "ongoing forever" maintenance set up for when we do any work. We just add our production groups / hostnames to that. And when we are done, we remove the hosts. It's easier than the ridiculously awful alternative of creating a "new" maintenance window each time. Seriously, the process to make a new maintenance window is horrendous, there should be another thread request for fixing that mess. /end_soapbox_rant
- 4. On resolution of the trigger, another Action would be fired off to run a command to remove all production groups from maintenance mode, again using the API.
-
- This may rely on hard coding the group name / group ID numbers, I'm still looking into the API methods for zabbix.
Also note, I presently don't have time to implement this as we are working on other projects. I wanted to share the idea in case you all thought it might be feasible. If I get around to it, I'll let you know how it works out.
|
|
If there is any chance you can read german, there is a wiki page which describes exactly this method:
https://znil.net/index.php?title=Zabbix_Standorte_Hostgruppen_bei_Nichterreichbarkeit_automatisch_in_den_Wartungsmodus_setzen_oder_daraus_entfernen
Maybe you can translate it via Google.
I really dislike this solution, but it solves a problem, we shouldn't have to solve.
|
|
I contacted sales at zabbix dot com three times since January about (co-)sponsoring this feature request. As it's one of the biggest features we are missing. I always got the answer, that they need more time to focus on 4.0 so I had no chance yet to get numbers or offer money.
I agree with all of you, that trigger dependencies could solve most of the issues, but I think that would require too much work in many of the cases.
I especially liked the example with a hypervisor going down, and all ICMP + Zabbix Agents checks would fail for the virtual machines. Because this would be like a real host dependency. (This special example would also include, that the Zabbix VMware Template feature of Host prototypes would have to work with an upcoming Host dependency feature!)
There are many ways this could be implemented, there could also be a second feature I would call Proxy dependency, as we all know that sometimes a Zabbix Proxy is unavailable and all Zabbix Agents behind that host would fire an event due to the nodata Trigger.
But on to the good news: Since the release of 4.0 our feature request is on the roadmap for 4.2:
https://www.zabbix.com/roadmap#v4_2
|
|
This feature It was postponed to 5.0?
|
|
Yes, https://www.zabbix.com/roadmap#v5_0
|
|
5.0 alpha is out. but I didn't see advanced event correlation in release note or document. is this still on the roadmap?
|
|
The work on that hasn't even been started yet. Despite it's on the official 5.0 roadmap it looks like it won't be there.
|
|
5.0 roadmap has only there tracking issues. but it seem none of them got resolved. wait next lts version...
|
|
Any official position about six last comments?
p.s. Cross my fingers to see this in 5.0
|
|
Any update on this?, Is anyone aware of any workaround for this at least? I´m monitoring 3 different sites and on a network issue event I get alerts for everyrhing on the other side of this network instead of a unique network alert. I hope I´m clear. Thanks everybody in advance!
|
|
To whom it may be of help, In 5.0 (ZBXNEXT-1891) you have a way of ignoring nodata() alerts coming from a proxy that is unavailable.
|
|
Given this was on the roadmap for 5.0 but didn't make it, is it likely to be 5.2?
|
|
I understand 5.2 or 5.4 is too early for the feature. but hope it can be made for 6.0. since it was on the roadmap of 5.0, I think it is reasonable to put it to 6.0 roadmap.
|
|
This feature was requested while Zabbix was in 1.6, now 11 years on and it continues to be ignored.
|
|
While I agree this would be a really nice and should have feature, this thread gave me an idea on how i might solve this for myself until/if this host dependency ever gets added.
- zabbix-agent, http, and snmp custom low level discovery macros that gather and add hierarchical metadata of mine. e.g. region dc, rack, server, subnet, LLDP neighbors and bgp neighbor info to each host dynamically and an in an automated way without any humans or complex automation outside of zabbbix.
- update my templates triggers to use those `region dc, rack, server, subnet, etc` LLD macros at the trigger level to fill in the custoum LLD macro 'variables'. example #15 here gives that https://www.zabbix.com/documentation/current/manual/config/triggers/expression#examples_of_triggers. This way the trigger level correlation of region, dc, rack, server, ip, application, etc is automatic and filled in dynamically on the fly using the value provided by my custom LLD maacros.
FWIW i haven't tested this idea, just had it after reading the zbxnext and some other related stuff. it may not be possible to use `macroname == macrovalue in triggers`, not sure. may have to use tags, or put the macro results in lld description for the host, and have the trigger to regex on the description. requires testing.
|
|
The way we have solved this for our network monitoring is by using tags to do trigger-based event correlation.
- We monitor our network mainly using SNMP polling. Host availability is monitored using ICMP ping.
- Periodically we check: the availability of a host, the status of the interfaces on the host, the status of the BGP sessions of the host with other hosts, the status of the MPLS LSPs of the host with other hosts, etc.
- When host_A is down we trigger an alarm:
- “host_A: Unavailable” with the tag “Unreachable: host_A”.
- All other hosts who have a BGP session with host_A will trigger an alarm because their BGP session with host_A is down. On hosts host_B, host_C, host_D, host_E, etc. this will trigger following alarms:
- “Host_B: BGP peer to host_A Down” with tag “bgp_to: host_A”
- “Host_C: BGP peer to host_A Down” with tag “bgp_to: host_A”
- “Host_D: BGP peer to host_A Down” with tag “bgp_to: host_A”
- “Host_E: BGP peer to host_A Down” with tag “bgp_to: host_A”
- …
- Under Event correlation we have 2 rules to correlate the “Host_X: BGP peer to host_A Down” alarms.
The reason that we have 2 rules is because with SNMP polling there is no way to know which alarm will be triggered first: “host_A: Unavailable” or “Host_X: BGP peer to host_A Down”.
- The first rule is meant to correlate the events in case the alarm “host_A: Unavailable" is raised before the alarms “Host_X: BGP peer to host_A Down” are raised.
- Condition: Old event tag Unreachable equals new event tag bgp_to
- Operation: Close new event
- --> As a result of this rule all new events with tag "bgp_to: host_A" will be closed.
- The second rule is meant to correlate the events in case the alarm “host_A: Unavailable" is raised after the alarms “Host_X: BGP peer to host_A Down” have been raised.
- Condition: Old event tag bgp_to equals new event tag Unreachable
- Operation: Close old events
- --> As a result of this rule all old events with tag "bgp_to: host_A" will be closed.
The overall result of this is that all “Host_X: BGP peer to host_A Down” alarms are resolved by the correlation rules.
Only the “host_A: Unavailable” alarm (the root cause) will remain open.
|
|
Hello,
It's really unfortunate that such a simple and requested feature does not exist in a world-renowned monitoring system like ZABBIX.
We thought we would put all our computer systems under this monitoring, what a disappointment to learn that the simple host dependency does not exist.
|
|
After all this years, and the implementation of ZBXNEXT-1891, I came to the conclusion, that Trigger dependencies are superior to host dependencies.
To realize host dependencies, Zabbix would have to know, what this dependency means. For example:
We have a switch and 5 Hosts. Switch monitored by SNMP+ICMP. Windows Hosts by Zabbix Agent and ICMP.
The Switch Host object consists of several Triggers, let's name two as an example: ICMP ping check failed and Firmware update available.
Zabbix doesn't know what these Triggers mean, it only know there are two Triggers which might fire. There is no way to tell, if one of this Triggers is active, should it mute all triggers from other hosts?
If the Firmware update Trigger fires, the Windows hosts wouldn't be affected and everything still runs smooth.
If the ICMP check Trigger fires, the Windows hosts would be affected and the ICMP and Zabbix agent nodata Trigger would fire.
Which in conclusion means, you don't want the ICMP and Zabbix agent nodata Trigger fire, when the ICMP check on the switch fails aka Trigger dependencies.
just my 2 cents: The longer I work with Zabbix, the less I have use for this feature request. In any use case I had in the past, I was able to solve it more elegant with the features I already have.
80% of my use cases resolved after ZBXNEXT-1891 and 20% by nice Trigger dependencies.
|
|
I just thought of a very simple way to implement it.
Give the possibility to assign to a host a main TEST (or object, or application). If this main test fails, the host will not be checked anymore, all objects will be disabled on it. (example ping) and finally give the possibility to an other host to depend on this test too, and in the case if the test is negative, the hosts that depend on it too...
Currently, when I have a network outage, Zabbix has queues, and goes up in load, I can't find a solution to put a dependency that the link falls and cut all SNMP icmp checks etc...
|
|
Things are just getting worse with 6.0, which drops the ability to modify dependencies on template-inherited triggers.
At the moment, if you have 100 hosts behind a router there is no way in Zabbix to avoid 100 useless and misleading alerts when the router goes down.
Very, very bad.
|
|
@Zabbix DevTeam there are some plane for Zabbix 6.2 or 6.4 for a possible way-out of these kind of behaviours?
I think on Kubernetes/VMWare (Dynamic Environment) the problem will be emphasized.
|
|
Please add host dependencies or at least give us back the feature to change dependency on template-inherited triggers. Lack of this solution is really hurting Zabbix scalability.
|
|
Do you mean the bug that was fixed in 6.0.5? ZBX-20613
|
|
Not quite. That's only controlling a single trigger, and there could be thousands on a host (worse if they're dynamically discovered).
What I'm wanting (and what I think others are talking about, too) is the ability to completely suspend the checks for a host based on a condition (i.e. the ICMP of an upstream device failing).
When an upstream device fails, zabbix then has lots of downstream devices sat in the unreachable queue... or worse they all alert with all of their triggers because they have timed out. This causes unneeded work on all sides. Suspending those items/triggers would reduce the workload.
|
|
@Marco, yes, that helps me, thanks!
I would still like to see dependencies simply set for entire host instead of per trigger, as even with the "fix"* from 6.0.5 this is still far from ideal.
*-not an actual bug, as I understand from the thread
|
|
Please we need this feature.
|
|
+1 Much needed feature!
We have many locations with multiple hosts. I don´t want to edit every trigger on every host to define a dependency to the availabilty of the appropriate router.
I also don´t want to create multiple templates for each location (e.g. Windows by Zabbix Agent for location A depends on router A, Windows by Zabbix Agent location B depends on router B,...) just to be able to set different trigger dependencies per location.
Thats way to much work and takes away flexibility in changing something in the template that should have affect to all hosts. It would be much easier to set the dependency per host or even better per host group (e.g. Servers/LocationA depending on host RouterA).
|
|
As a workaround, you may consider Global event correlation, as explained in this video: https://www.youtube.com/watch?v=uTsGAj_BLhs by Aigars Kadikis, which shows a topology-related scenario.
If you never used event correlation before, please note that it will take a while to understand and setup it, but it can be a viable - though not perfect - solution.
|
|
Hi Guys,
we can expect something enhancement on this topic for 7.2? Thanks so much
|
Generated at Sun Aug 03 16:59:22 EEST 2025 using Jira 9.12.4#9120004-sha1:625303b708afdb767e17cb2838290c41888e9ff0.