-
Type:
Problem report
-
Resolution: Fixed
-
Priority:
 Trivial
Trivial
-
Affects Version/s: 4.0.12
-
Component/s: Server (S)
-
Environment:Zabbix4.0.12
-
Sprint 56 (Sep 2019), Sprint 57 (Oct 2019)
-
0.5
The following script causes problems every 2 seconds and recovers every 2 seconds.
#!/bin/bash
count=1
until [ $count -gt $1 ]
do
zabbix_sender -z 127.0.0.1 -s "Zabbix server" -k sender -vv -o 0 >> /dev/null 2>&1
sleep 2
zabbix_sender -z 127.0.0.1 -s "Zabbix server" -k sender -vv -o 1 >> /dev/null 2>&1
sleep 1
zabbix_sender -z 127.0.0.1 -s "Zabbix server" -k sender -vv -o 0 >> /dev/null 2>&1
sleep 2
zabbix_sender -z 127.0.0.1 -s "Zabbix server" -k sender -vv -o 1 >> /dev/null 2>&1
sleep 2
((count++))
if [ $count -eq $1 ]
then
break
fi
done
The argument is the repeat count.
It occurred with a probability of 1/1000 in my environment.
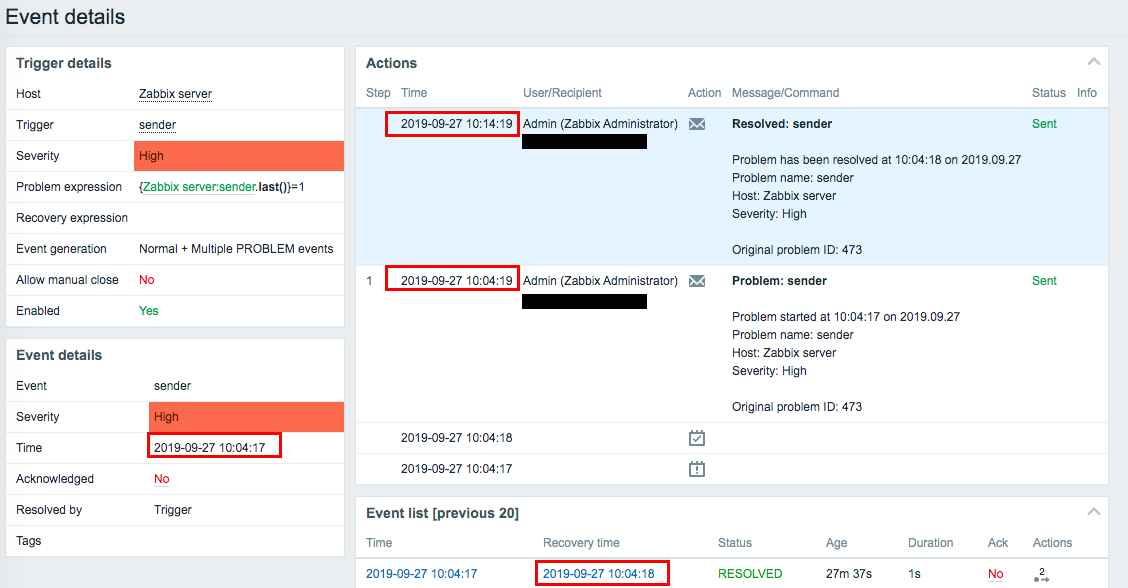
The recovery time is displayed on the "Event details", but no recovery alert has been sent.
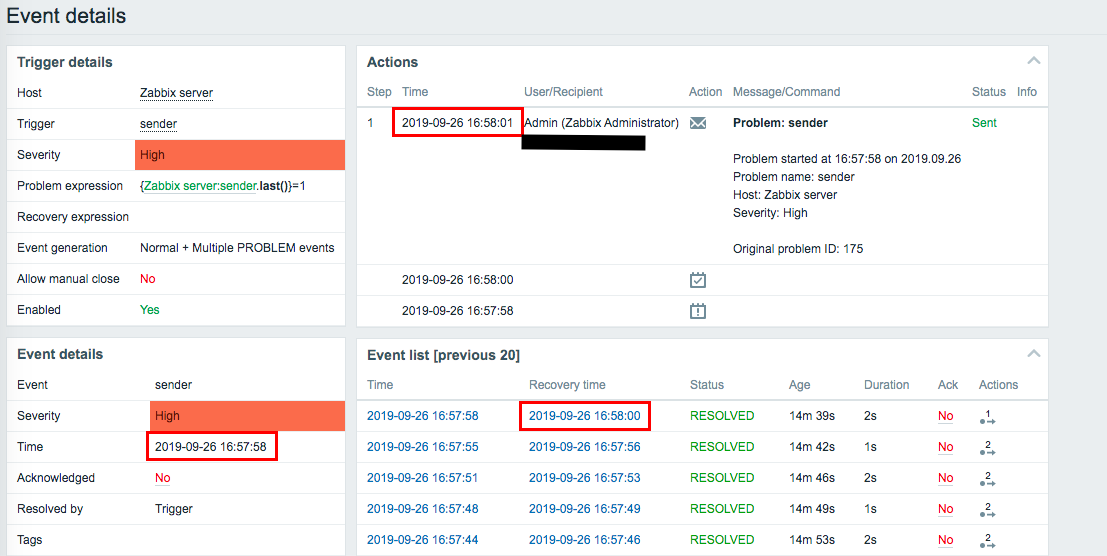
The confirmed time is 17:30.
+---------+--------+--------+----------+------------+-------+--------------+-----------+--------+----------+ | eventid | source | object | objectid | clock | value | acknowledged | ns | name | severity | +---------+--------+--------+----------+------------+-------+--------------+-----------+--------+----------+ | 175 | 0 | 0 | 15911 | 1569484678 | 1 | 0 | 651448808 | sender | 4 | | 176 | 0 | 0 | 15911 | 1569484680 | 0 | 0 | 674482223 | sender | 0 | +---------+--------+--------+----------+------------+-------+--------------+-----------+--------+----------+ 2 rows in set (0.00 sec)
1569484678 : 2019/09/26 16:57:58
1569484680 : 2019/09/26 16:58:00
I "select" a table that seems relevant.
MariaDB [zabbix]> select * from escalations where eventid=175; +--------------+----------+-----------+---------+-----------+------------+----------+--------+--------+---------------+ | escalationid | actionid | triggerid | eventid | r_eventid | nextcheck | esc_step | status | itemid | acknowledgeid | +--------------+----------+-----------+---------+-----------+------------+----------+--------+--------+---------------+ | 51 | 3 | 15911 | 175 | 176 | 1569488281 | 1 | 2 | NULL | NULL | +--------------+----------+-----------+---------+-----------+------------+----------+--------+--------+---------------+ 1 row in set (0.00 sec)
1569488281 : 2019/09/26 17:58:01
MariaDB [zabbix]> select eventid,subject,clock from alerts where eventid in (175,176); +---------+-----------------+------------+ | eventid | subject | clock | +---------+-----------------+------------+ | 175 | Problem: sender | 1569484681 | +---------+-----------------+------------+ 1 row in set (0.00 sec)
1569484681 : 2019/09/26 16:58:01
It looks like this to me:
alerts : clock + 1h = escalations:nextcheck
"Default operation step duration" is 1h in the action settings.
The confirmed time is 18:00.
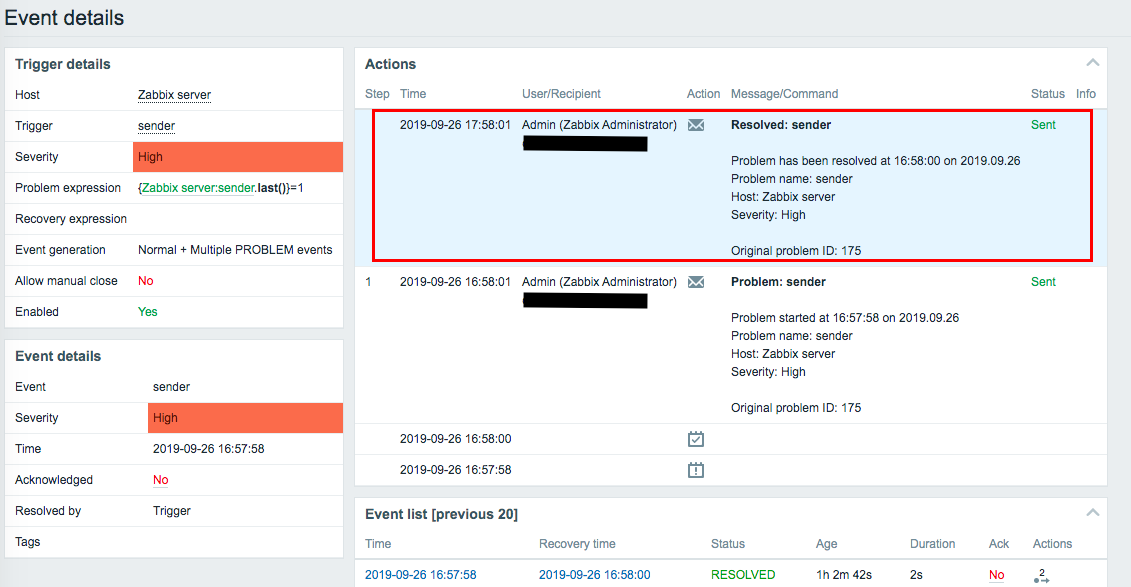
MariaDB [zabbix]> select eventid,subject,clock from alerts where eventid in (175,176); +---------+------------------+------------+ | eventid | subject | clock | +---------+------------------+------------+ | 175 | Problem: sender | 1569484681 | | 176 | Resolved: sender | 1569488281 | +---------+------------------+------------+ 2 rows in set (0.00 sec)
1569484681 : 2019/09/26 16:58:01
1569488281 : 2019-09-26 17:58:01
Recovery alert was registered about 1 hour after recovery.

{kind=link}
{kind=link}
{kind=link}